Towards Universal Dialogue State Tracking (EMNLP 2018)
- 6 mins- Paper Link: https://arxiv.org/abs/1810.09587
- Author
- Liliang Ren, Kaige Xie, Lu Chen and Kai Yu
- Shanghai Jiao Tong University
- Published at
- EMNLP 2018 (Oral)
Abstract
- Dialogue State Tracking (DST)란 dialogue system에 있어서 매우 중요한 파트로서, 매 대화 턴 별로 유저의 목표(goal)에 대한 가능성을 예측하는 문제임
- 하지만 대부분의 최근 어프로치들은 넓은 범위의 대화 도메인으로 인해 아래의 한계 및 어려움이 있음
- Ontology의 슬롯 값이 동적으로 변하는 환경에서 잘 작동하지 않음
- 슬롯의 개수에 비례해서 모델 파라미터 크기가 커짐
- Hand-crafted lexicon feature를 기반으로 함
- 이런 문제들을 해결하기위해, 우리는 Universal Dialogue State Tracker인 StateNet을 제안함
- StateNet은 특징 및 contribution은 다음과 같음
- 모든 슬롯에 대해 파라미터를 공유하기 때문에 슬롯의 개수에 대해 모델 크기가 독립적임
- Lexicon feature (explicit semantic dictionaries) 대신에 pre-trained word vector를 사용함
- DST 분야의 대표적인 데이터셋인 DSTC와 WOZ에 대해서 state-of-the-art 성능을 보임
- 또한 실험 결과를 통해 위에 언급한 한계점들을 극복했다는 것을 보여줌
1. Introduction
- Task-oriented dialogue system은 크게 input, output, control, 3개의 모듈로 구성됨
- Control은 흔히 dialogue management라고 불리며 이 모듈은 dialogue state tracking과 decision making이라는 2가지 미션이 있음
- State tracker는 매 대화 턴마다, input 모듈로부터 받은 정보를 기반으로 시스템의 내부 state를 유지시킴
- 대화를 진행시키기 위해 dialogue policy에 따라서 이 dialogue state를 기반으로 머신은 액션을 결정함
- Dialogue state는 전체 대화에 대한 머신의 이해를 인코딩한 것
- 전통적으로 이 state는 3가지 컴포넌트를 갖음: 1) user’s goal, 2) user’s action, 3) dialogue history. 이중에서 user’s goal이 가장 중요. user’s goal은 slot-value의 쌍으로 표현함
-
우리는 이 논문에서 user’s goal을 tracking하는 부분만을 집중해서 다룰 것
- DST를 위한 rule-based model, generative statistical model, discriminative statistical model 등의 다양한 어프로치가 제안됨. SOTA는 딥러닝 기반
- 이 어프로치들에는 다음의 몇 가지 한계점들이 있음
- 특정 도메인의 ontology만을 사용할 수 있음. 다른 도메인 사용 불가
- 예를 들어, 관광 도메인을 다루다가 레스토랑 도메인을 다루려면 ontology를 교체해야 함
- 각 slot에 대한 모델이 다름. 슬롯마다 모델이 필요
- 따라서 슬롯이 늘어나면 전체 모델의 파라미터도 비례하게 증가
- Semantic dictionary를 기반의 feature를 사용함
- Large scale 도메인에서의 slot과 value에 대해 이런 dictionary를 구축하는 것은 매우 어려움
- 특정 도메인의 ontology만을 사용할 수 있음. 다른 도메인 사용 불가
- 이런 문제를 해결하기 위해 Universal Dialogue State Tracker, 일명 StateNet을 제안함
- StateNet은 각 state slot에 대해 dialogue history의 고정 길이 representation을 생성함
- 그리고 state와 후보 representation 간의 벡터 거리를 통해 decision을 함. 후보는 동적으로 변할 수 있음
- StateNet은 3가지 데이터가 필요함
- User utterance
- Machine의 act 정보
- slot과 value의 이름(literal)
- StateNet은 모든 slot에 대해 모든 파라미터를 공유함. 따라서 slot 간의 지식을 트랜스퍼할 수 있을 뿐 아니라, 파라미터도 줄일 수 있음
2. StateNet: A Universal Dialogue State Tracker
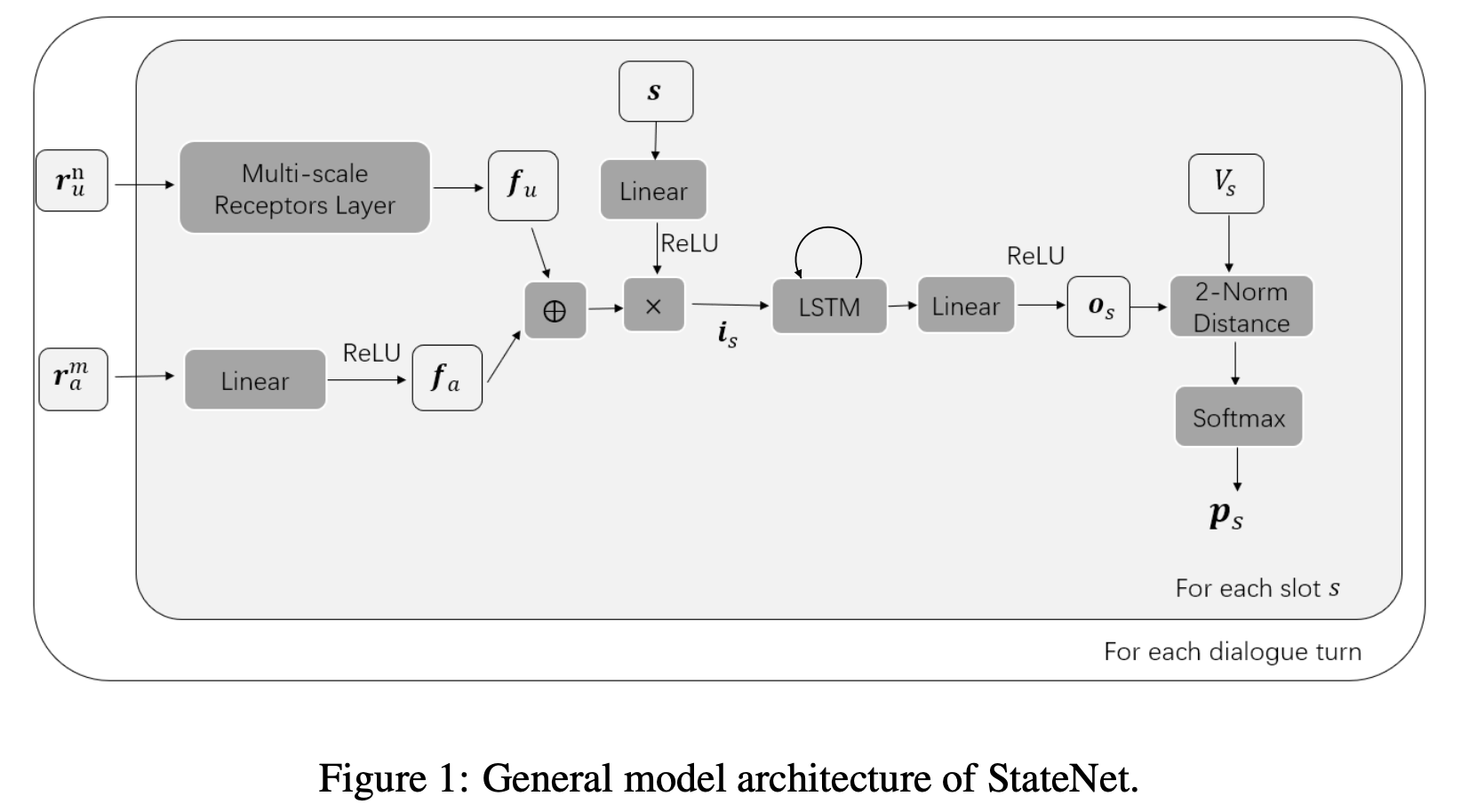
- 각 대화 턴마다 StateNet은 다음을 input으로 받음
- Multiple n-gram user utterance representation $r_u^n$
- m-gram machine act representation $r_a^m$
- value set $V_s$
- word vector of slot $s$
- 목표는 slot $s$ 에 대해 적절한 value $v \in V_s$ 를 구하는 것!
- StateNet은 내부 dialogue state를 tracking하기 위해서 LSTM을 적용함
- StateNet은 매 대화 턴마다 각 slot에 대해서 value set, $V_s$, 에 대한 확률 분포를 output으로 내보냄
- $p_s = \text{StateNet}(r_u^n, r_a^m, s, V_s)$
- 전체 모델 아키텍쳐는 Figure 1과 같음
2.1 User Utterance Representation
- Utterance의 각 단어 representation을 구함
- n-gram representation을 구함. n개의 단어 representation의 concat
- 각 n-gram representation의 합이 최종 user utterance representation $r_u^n$
2.2 Multi-scale Receptors Layer
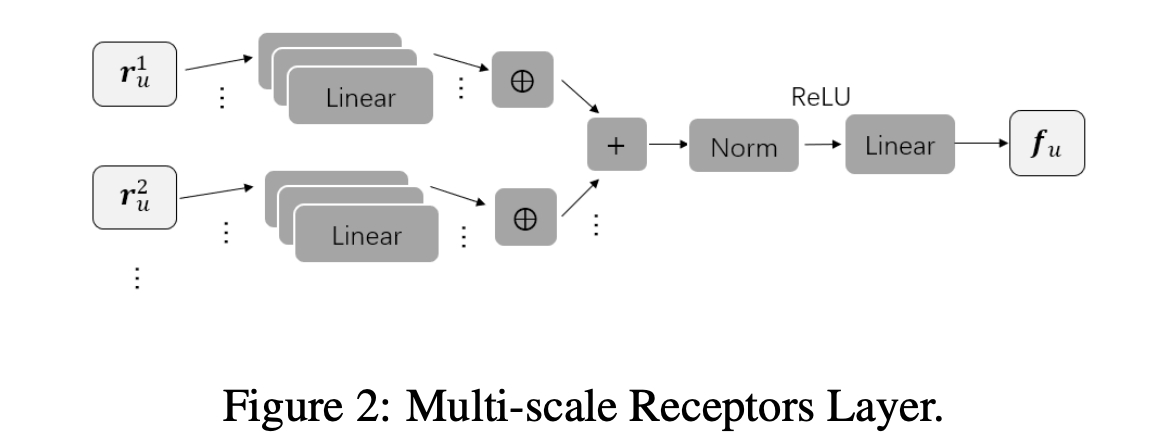
- k-gram (1<=k<=n)의 representation 형태가 k개를 concat을 하는 방식이기에 k에 따라 representation 모양이 다름. 따라서 벡터 차원을 맞춰주기 위해 linear layer를 $c$ 개 붙임
- $\hat{r}u^k = \text{concat}{j=1}^c (W_k^j r_u^k + b_k^j)$
- $W_k^j$ 는 k-gram에 대한 j 번째 linear layer. output 차원은 모두 $N_c$ 로 동일함 (차원을 맞춰야 함)
- 즉 모든 k-gram에 대해서 $N_c$ 차원으로 $c$ 번 projection 시킴. $c$ 는 채널의 개념이지 싶음
- 최종적으로 $c$ 개의 linear layer의 output을 모두 concat하여 user utterance에 대한 k-gram의 representation $\hat{r}_u^k$ $\in \mathbb{R}^{N_c \times c}$ 을 구함 (Ba et al., 2016)
- 모든 k-gram의 representation을 모두 합하고 layer normalization, relu, linear (project to ) 를 태워서 최종 user feature vector $f_u \in \mathbb{R}^{N_c}$ 를 구함
- $f_u = \text{Linear}(\text{ReLU}(\text{LayerNorm}(\sum_{k=1}^{n} \hat{r}_u^k)))$
2.3 Machine Act Representation
- Machine act가 뭔지 잘 모르겠음
- 쨋든 주어진 데이터셋에 있는 machine act로 vocab을 만들고 아래와 같이 machine act feature vector $f_a \in \mathbb{R}^{N_c}$ 를 구함
- $f_a = \text{ReLU}(\text{Linear}(r_a^m))$
2.4 Slot Information Decoding
- Slot에는 area, food 등이 해당되는데, 주로 하나의 단어 혹은 짧은 구로 이루어져 있음
- 즉 slot의 이름(area, food) 그 자체에 대한 word vector를 사용하겠다는 컨셉.
- Slot의 representation $s$ 를 구함. 여러 단어(구)의 경우 각 단어 벡터의 합으로 표현
- 위의 user와 machine feature와의 연산을 위해 $2N_c$ 짜리 linear 태움
-
$f_s = \text{ReLU}(\text{Linear}(s))$
- 지금까지 구한 user, machine, slot feature를 모두 합해서 turn-level feature vector $i_s$ 를 만들 것임
- $i_s = f_s \otimes (f_u \oplus f_a)$
- user와 machine feature를 concat하고 ($2N_c$ 차원), 그 결과를 slot feature와 point-wise multiplication함
- 이렇게 구한 turn-level feature vector는 large magnitude signal을 증폭되는 경향이 있음 (뭔 소리지… 당연한 거 아닌가)
2.5 Fixed-length Value Prediction
- 각 턴에 대해서 turn-level feature vector $i_s$ 에 대해 LSTM을 태움
- 그렇게 해서 최종적으로 fixed-length value prediction vector $o_s \in \mathbb{R}^{N_w}$ 를 얻음
- $o_s = \text{ReLU}(\text{Linear}(\text{LSTM}(i_s, q_{t-1})))$
- 이를 이용해서 value representation과의 유사도를 구해 가장 적절한 value를 구할 예정임
- 결국 지금까지의 작업들을 살펴보면, 대화 상황 (utterance, machine feature)과 context (LSTM)를 고려한 slot의 representation $o_s$ 을 만드는 과정이라고 볼 수 있음
2.6 2-Norm Distance
- 위에서 구한 slot representation과 $V_s$ 을 구성하는 value $v_i$ 들 사이의 유사도를 구하는 부분
- 원하는 value가 없을 수 있기 때문에 “none” 이라는 value를 추가함
-
$p_s(v_i) = \text{Softmax}(- o_s - v_i )$, $v_i$ 는 $v_i$ 의 representation vector - 위 식이 뭔가 잘못된 것 같음. $p_s(V_s)$ 뭐 이런 식이 되어야 할 것 같음. 여튼 의미는 모든 value 단어들에 대해 유사도를 구하고 이에 대해 softmax를 취한다는 것
- CE로 업데이트
최종적으로 정리하면, StateNet은 user utterance와 word vector로 표현 가능한 semantic slot과 value가 필요함. word vector는 pre-trained를 쓰고 fine-tuning은 하지 않음. StateNet은 위 조건만 만족하면 되기에 새로운 slot이나 value를 얼마든지 추가할 수 있음. 이런 이유로 StateNet을 “universal” dialogue state tracker라고 얘기한 것임
3. Experiments
- DSTC2와 WOZ 2.0으로 성능 평가
- Slot = {food, pricerange, area}
- 제안하는 모델에 대해 3가지 variation을 둠
- StateNet: slot 별 파라미터 공유하지 않음. 3개의 slot에 대해 3개의 모델을 만듬. Initialization 용도의 pre-trained model도 사용하지 않음
- StateNet_PS: slot 별 파라미터 공유. 하나의 모델로 동일한 대화 정보에 대해 3개의 slot에 대해 예측을 진행. StateNet에 비해 1/3의 파라미터 크기
- StateNet_PSI: 파라미터 공유와 함께 pre-trained model로 initialization함. 여기서 pre-training이란, 각 single slot에 대해서만 모델을 학습시키는 과정을 말함. single slot에 대한 모델 중 validation 성능이 제일 좋았던 모델의 weight로 multi slot 모델을 initialization하는 거임. (논문에 food에 대한 예시가 나오는데 설명이 이상함)
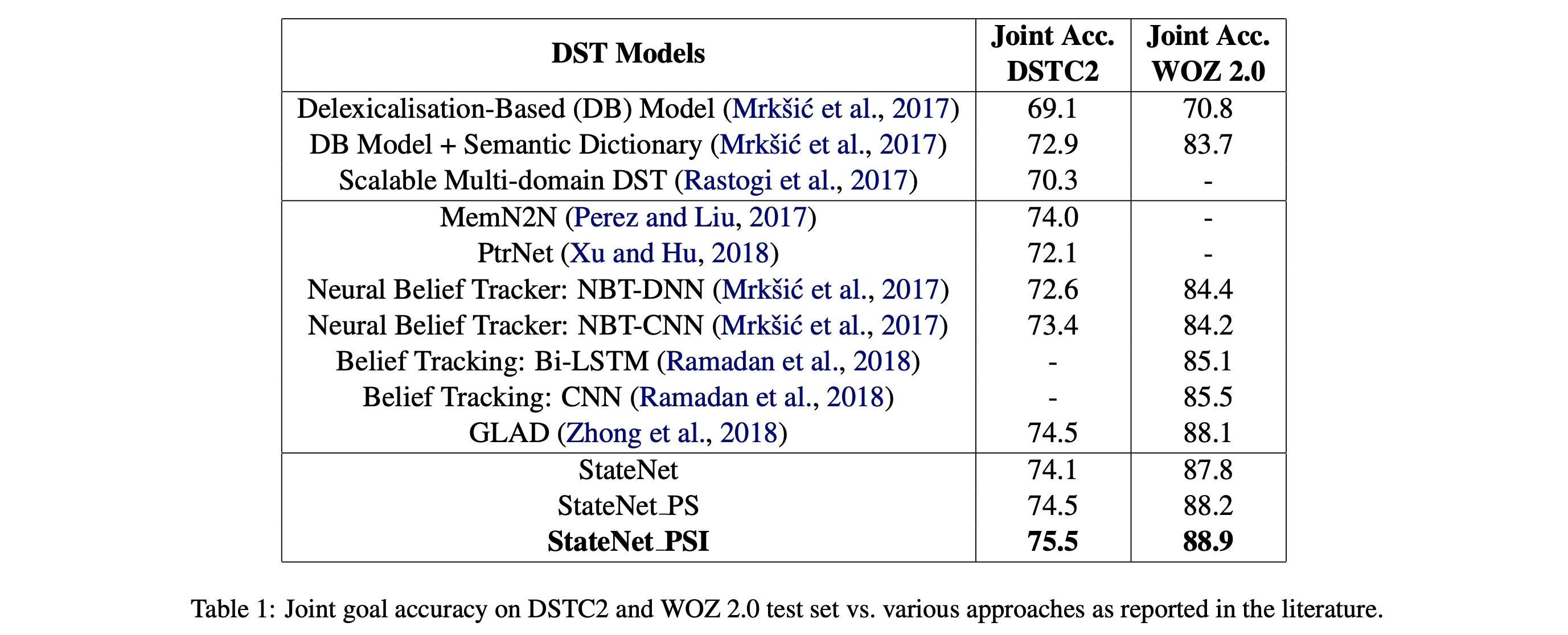
- SOTA 찍음. Lexical feature 쓴 모델들보다도 좋음
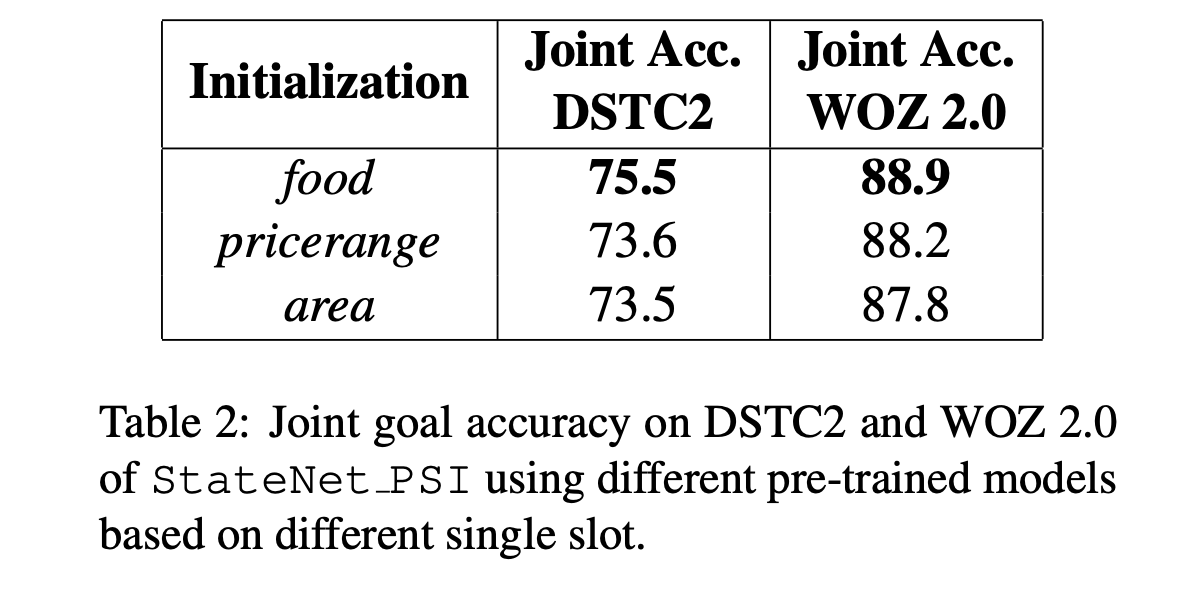
- Pre-training은 food에 대해서 하는 게 가장 성능이 좋았음
- 그 이유는 food slot이 가장 어려운 문제에 해당하는데 이에 대해서 초기 학습을 한 것이 전체 성능을 높이는데 기여했을 것이라고 추측. Weakness slot에 대한 boosting의 개념으로 생각해볼 수 있다는 것

Joohong Lee
Machine Learning Researcher