Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks (EMNLP 2019)
- 3 mins- Paper Link: https://arxiv.org/abs/1908.10084
- Author
- Nils Reimers and Iryna Gurevych
- Technische Universitat Darmstadt
- Published at
- EMNLP 2019
Abstract
- BERT(Devlin et al., 2018)나 RoBERTa(Liu et al., 2019)가 semantic textual similarity(STS)와 같은 sentence-pair regression tasks에서 state-of-the-art 성능을 보임
- 하지만 이런 모델을은 input sentence pair가 한번에 feeding 되어야 한다는 단점이 있음
- 만약 10000개의 문장 중 가장 유사한 pair를 찾는다고 하면 약 50M의 inference computations이 필요함 (65 hours)
-
이런 BERT의 구조는 semantic similarity search에 적합하지 않음
- 이 논문에서는 BERT를 siamese and triplet network 형태로 바꾼 Sentence-BERT(SBERT)를 제안함
- 이런 네트워크 구조는 문장의 의미를 sentence embedding이 효과적으로 표현할 수 있게 해주며, cosine-similarity를 통해 쉽게 유사도를 계산할 수 있게 해줌
- SBERT를 이용하면 위에서 BERT/RoBERTa가 65시간 걸리던 걸 5초만에 끝낼 수 있음
- 우리가 제안하는 SBERT/SRoBERTa는 STS를 비롯한 transfer tasks에서 다른 SOTA sentence embedding method를 outperform 했음
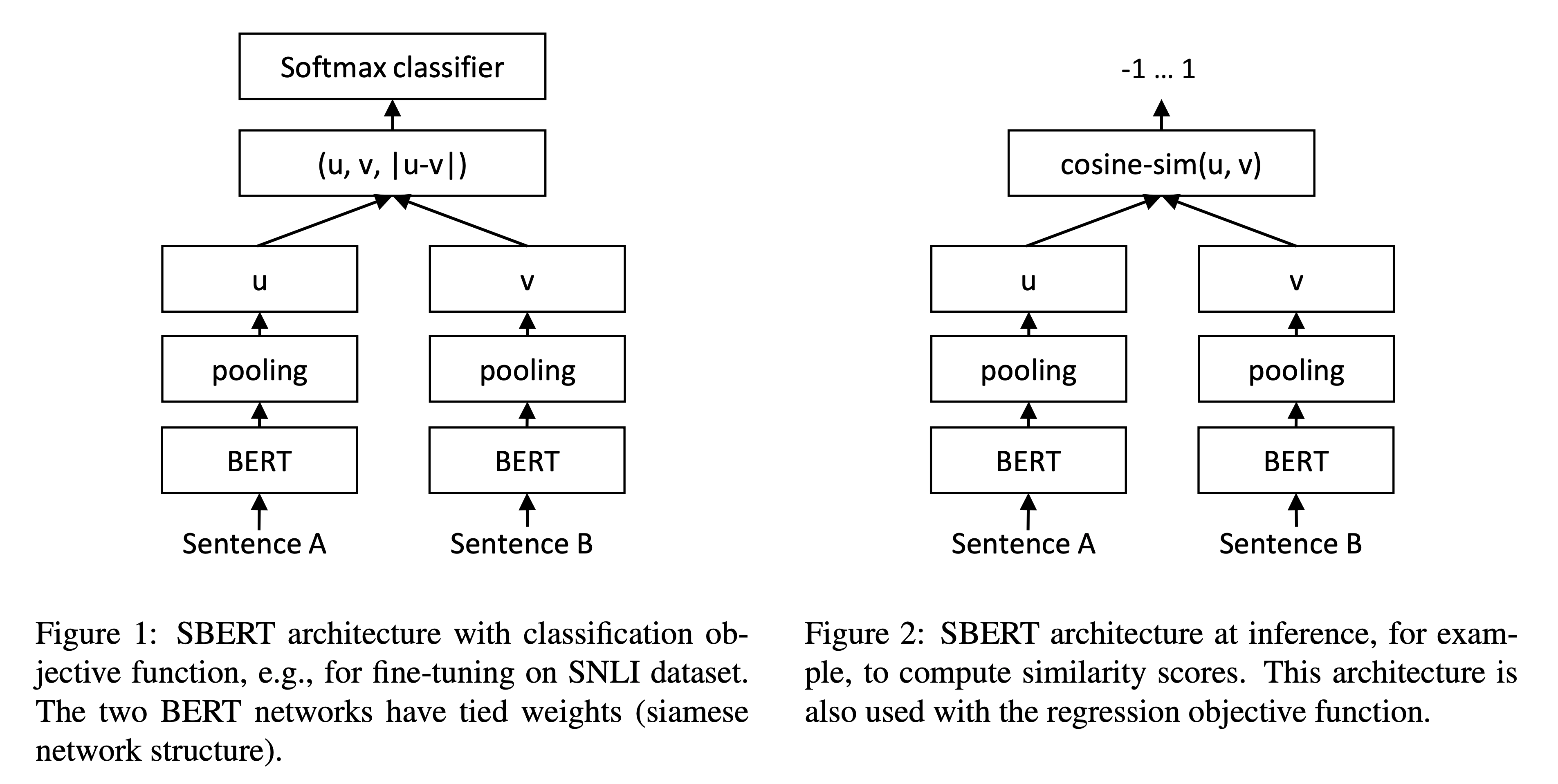
3. Model
Pooling Strategy
- CLS: Output of CLS-token
- MEAN: Mean of all output vectors
- MAX: Max-over-time of the output vectors
Objective Functions
-
Classification Objective Function
\[o = \text{softmax}(W_t(u, v, |u-v|))\]- $W_t \in \mathbb{R}^{3n \times k}$
- Optimize cross-entropy loss
- dipicted in Figure 1
-
Regression Objective Function
\[o = \sigma(\text{cosine\_similarity}(u, v))\]- Cosine similarity between two sentence embedding $u$ and $v$
- Optimize mean-squared-error loss
- dipicted in Figure 2
-
Triplet Objective Function
- Anchor sentence $a$ , positive sentence $p$ , negative sentence $n$ 이 있다고 해보자
- Triplet loss는 $a$ 와 $p$ 사이의 거리는 가깝게, $a$ 와 $n$ 사이의 거리는 멀게 해줌
- 아래와 같은 loss function을 minimize함
- Distance metric으로는 Euclidean을 사용
- $\epsilon$ 은 1로 세팅
3.1. Training Details
- 아래의 두 dataset을 조합하여 학습(fine-tuning)함
- We fine-tune SBERT with a 3-way softmaxclassifier objective function for one epoch
- Batch size = 16
- Adam optimizer
- Learning rate = 2e-5
- Linear learning rate warm-up over 10% of training data
- Pooling strategy = MEAN
4. Evaluation - Semantic Textual similarity
4.1. Unsupervised STS
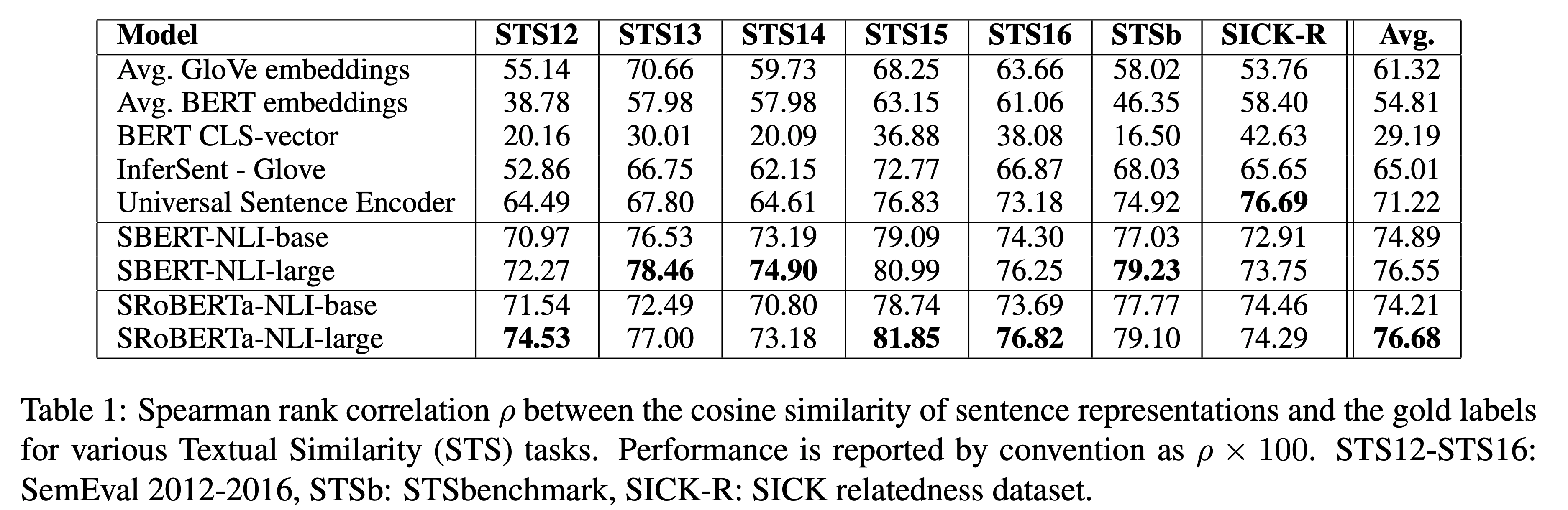
- 각 모델로부터 얻은 sentence embedding으로 구한 cosine similarity와 gold label 사이의 correlation을 보임
- 위의 모든 모델들은 STS 데이터를 학습한 적이 없음
- 즉, STS에 대한 학습 없이 sentence embedding을 뽑아서 consine similarity를 구한 것
- (NLI 데이터를 학습해서 그런지 SBERT/SRoBERTa가 성능이 꽤 좋음)
4.2. Supervised STS

- 이번에는 STS를 학습(fine-tuning)한 버전
- 실험을 위한 두가지 setup이 있음
- Only training on STSb
- First training on NLI, then training on STSb
- NLI를 학습한 경우가 1-2 포인트 정도 더 좋았음
- BERT cross-encoder는 NLI를 학습하면 3-4 포인트나 더 향상됨
- BERT와 RoBERTa 사이에는 큰 차이는 없다고 보임
5. Evaluation - SentEval
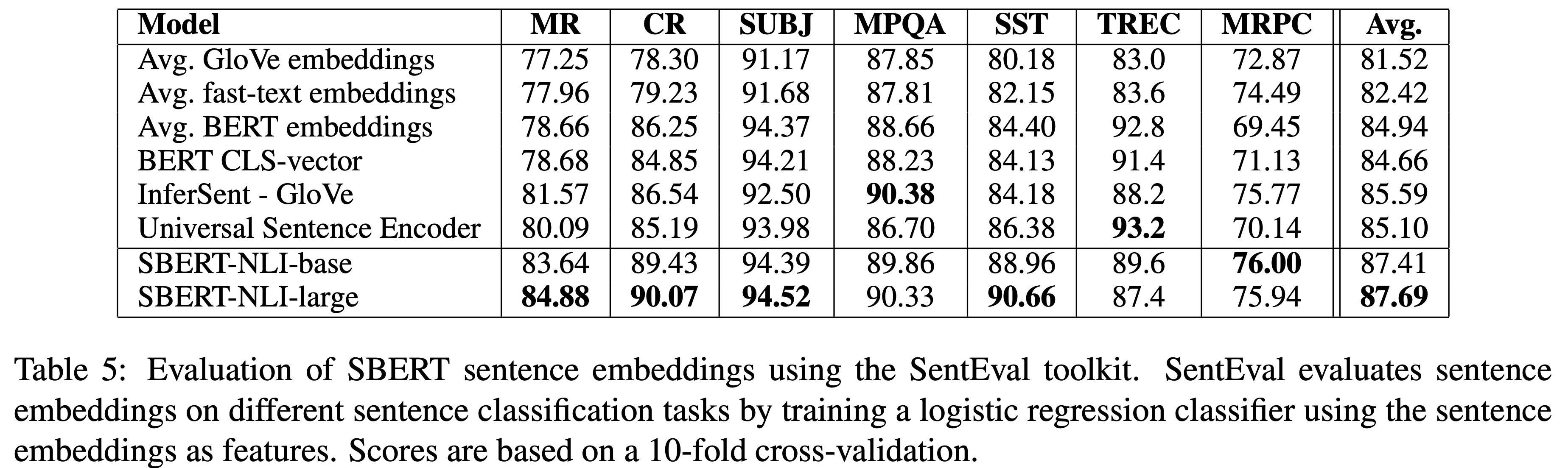
- SentEval(Conneau and Kiela, 2018)
- MR: Sentiment prediction for movie reviews snippets on a five start scale (Pang and Lee, 2005)
- CR: Sentiment prediction of customer product reviews (Hu and Liu, 2004)
- SUBJ: Subjectivity prediction of sentences from movie reviews and plot summaries (Pang and Lee, 2004)
- MPQA: Phrase level opinion polarity classification from newswire (Wiebe et al., 2005)
- SST: Stanford Sentiment Treebank with binary labels (Socher et al., 2013)
- TREC: Fine grained question-type classification from TREC (Li and Roth, 2002)
- MRPC: Microsoft Research Paraphrase Corpus from parallel news sources (Dolan et al., 2004)
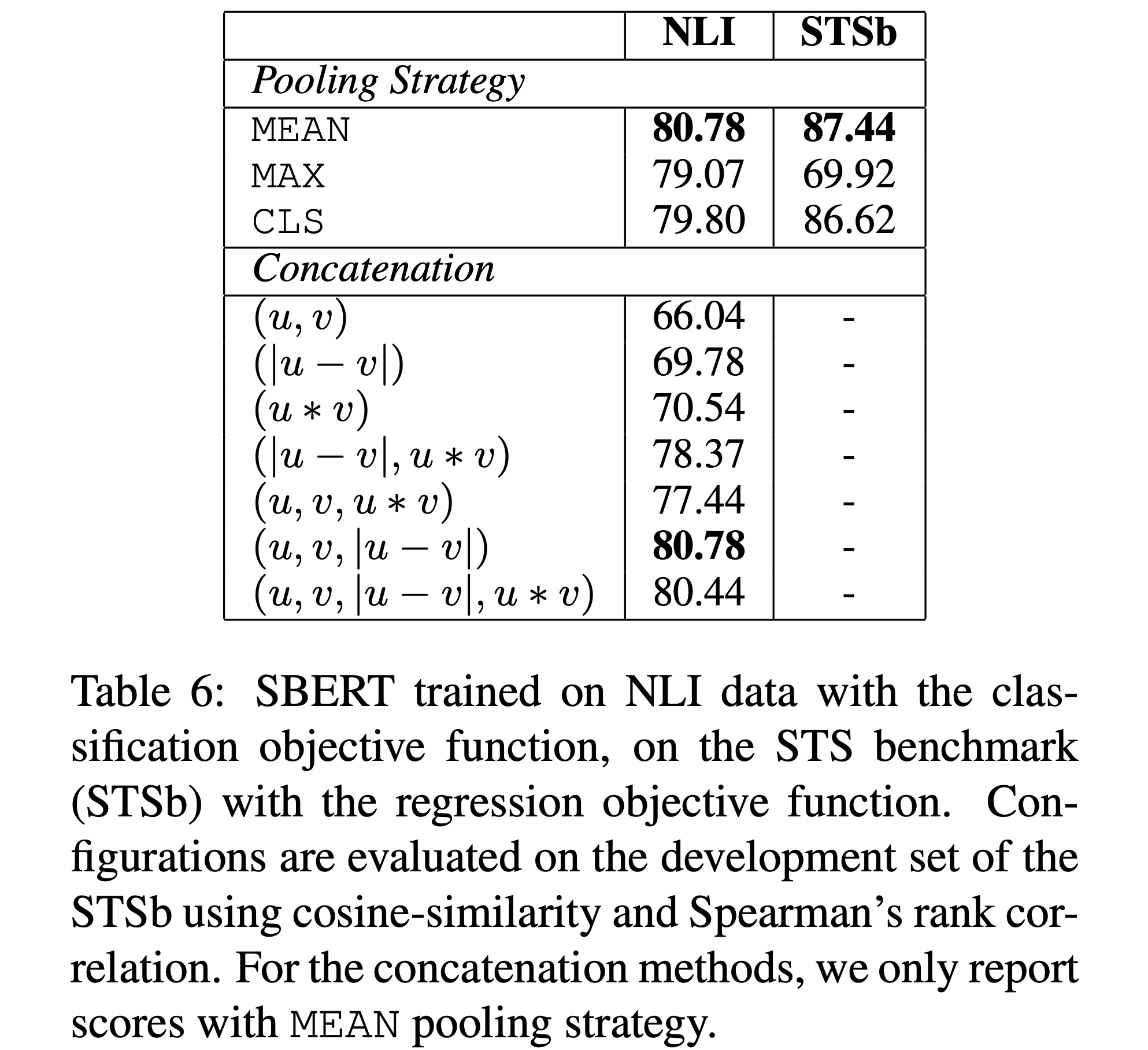
6. Ablation Study

Joohong Lee
Machine Learning Researcher