Poly-encoders: Transformer Architectures and Pre-training Strategies for Fast and Accurate Multi-sentence Scoring (ICLR 2020)
- 6 mins- Paper Link: https://arxiv.org/abs/1905.01969
- Author
- Samuel Humeau, Kurt Shuster, Marie-Anne Lachaux, Jason Weston
- Facebook AI Research
- Published at
- ICLR 2020
Abstract
- Sequence 간의 pairwise 비교를 하는 태스크에 대해 보통 1) sequence pair를 한번에 인코딩(full self-attention)하는 Cross-encoder 방식과 2) sequence pair를 각각 인코딩하는 Bi-encoder 방식을 사용합니다.
- Cross-encoder는 self-attention 과정에서 두 sequence가 서로를 token-level로 참조할 수 있기 때문에 성능이 좋지만, pair에 대한 인코딩을 해야 하기 때문에 실제로는 너무 느려서 사용하기 어렵습니다.
- Bi-encoder는 각 문장에 대해서만 인코딩하면 되기 때문에 빠르지만 성능이 약간 떨어지는 단점이 있습니다.
- 이런 두 approach 한계를 커버하는 Poly-encoder를 제안합니다.
- Poly-encoder를 포함한 3개의 인코더와 학습 방법에 대해서 실험을 통해 비교하였고, Cross-encoder보다는 빠르고 Bi-encoder 보다는 정확한 성능을 얻었습니다.
- 또한 Poly-encoder는 4개의 태스크에 대해서 state-of-the-art 성능을 기록하였습니다.
Tasks
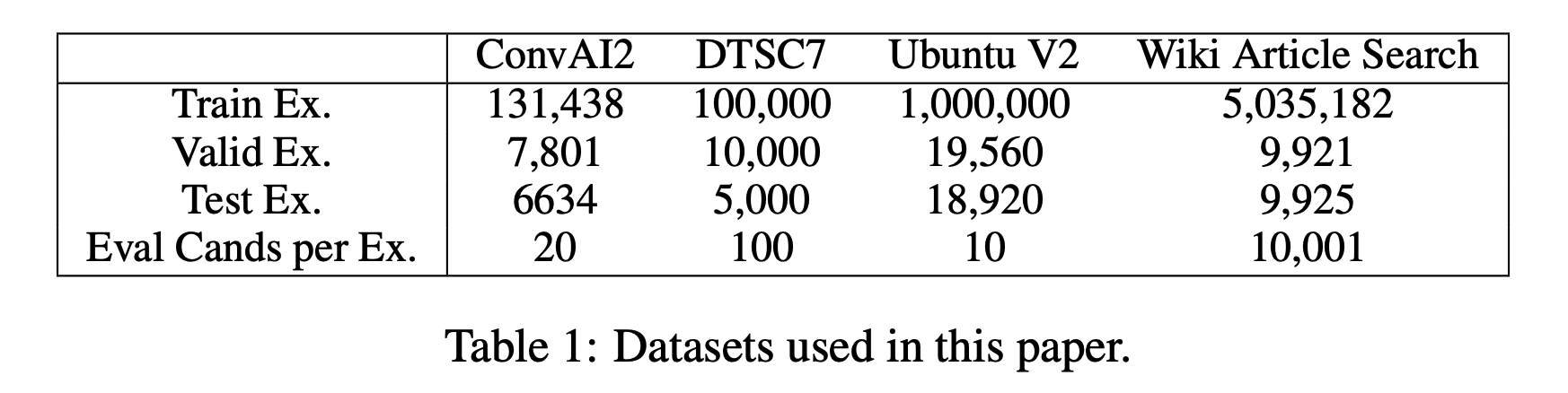
- Sentence selection in dialogue: 주어진 대화 컨텍스트의 다음에 올 말로 적절한 것 찾기 (객관식 10~20개)
- ConvAI2
- DSTC7 challenge Track 1
- Unbuntu V2 corpus
- Article search in IR: 주어진 문장이 등장한 article 찾기 (객관식 10000개)
- Wikipedia Article Search
Methods
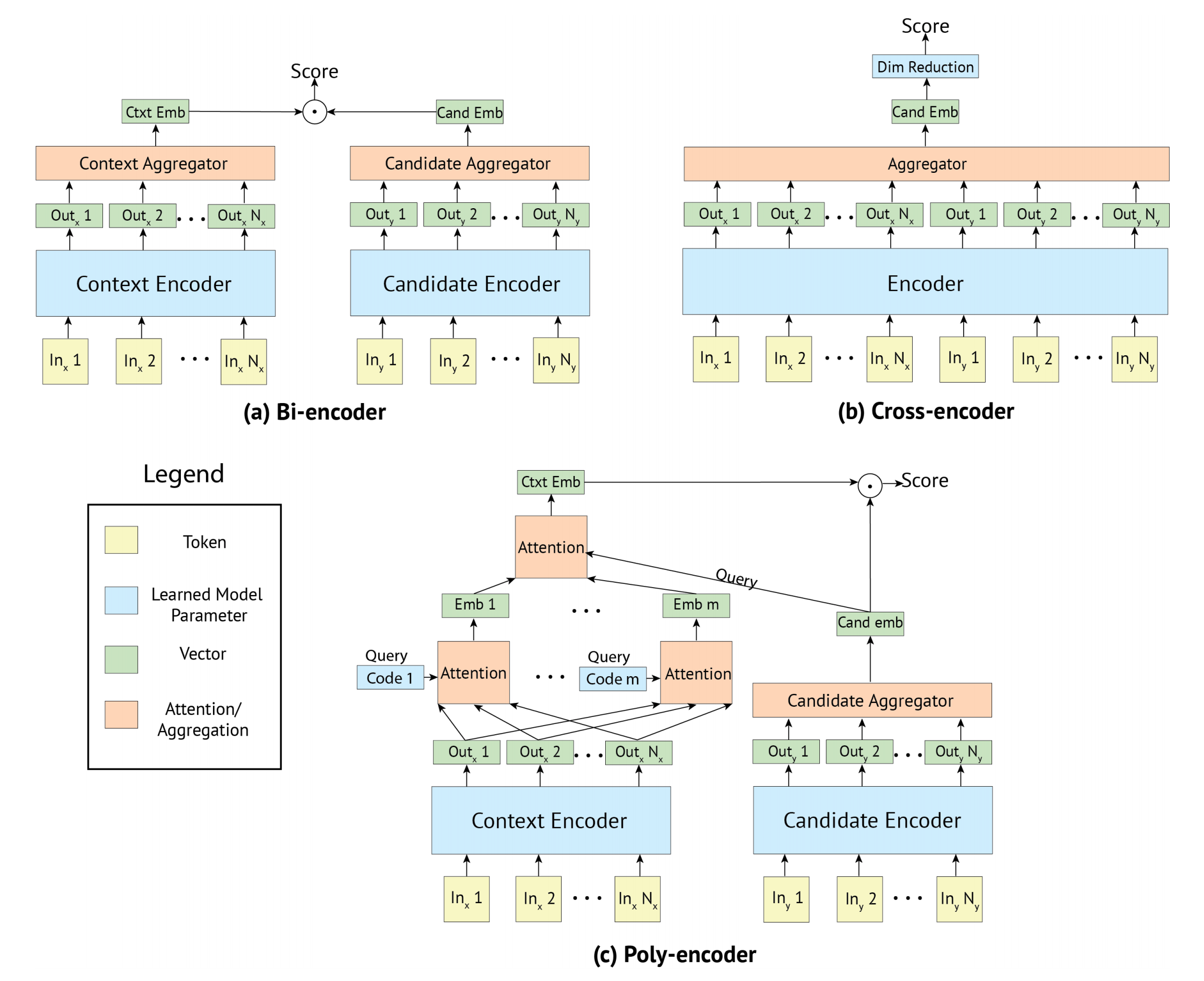
Bi-encoder
-
Figure 1 (a) 처럼 Context Encoder와 Candidate Encoder가 각각 context 문장과 해당 context 다음에 올 후보 문장을 인코딩하는 구조입니다. 수학적으로 다음과 같습니다.
\[y_{ctxt} = red(T_1 (ctxt)), \quad y_{cand} = red(T_2 (cand))\]- $T(x) = h_1, …, h_N$ 는 Transformer Encoder의 output을 의미하며, $red(\cdot)$ 은 이런 sequence output을 하나의 벡터로 변환시킵니다.
- 최종적으로 얻어지는 $y$ 는 각 Encoder의 Contextualized Embedding을 의미합니다.
-
인코딩 결과로 Context Embedding, Candidate Embedding을 얻을 수 있고, 두 벡터의 내적(dot-product)을 통해서 다음 문장으로 적절한가에 대한 점수를 계산합니다. 수학적으로 다음과 같습니다.
\[s(ctxt, cand_i) = y_{ctxt} \cdot y_{cand_{i}}\] - 위와 같은 방식으로 주어진 $n$ 개의 후보들에 대해서 점수를 구하고, 가장 높은 점수의 후보 문장을 주어진 context 다음에 올 문장이라고 간주합니다.
- 학습할 때는 batch 내의 샘플을 negatives로 사용하여 cross entropy를 최소화시키도록 학습합니다.
- 하나의 batch는 [($ctxt_1$, $cand_1$), ($ctxt_2$, $cand_2$), …, ($ctxt_n$, $cand_n$)] 와 같이 구성됩니다.
- 이때 첫번째 $ctxt_1$에 대한 loss는 $cand_1$는 positive 나머지 $cand_{j={2, …, n}}$는 negative로 하여, 즉 target을 [1, 0, …, 0]로 하여 cross entropy loss를 계산할 수 있음. 이를 모든 $ctxt$에 대해서 계산하고 이 loss를 최소화하도록 학습합니다.
- Bi-encoder는 context와 candidate을 독립적으로 인코딩하기 때문에, 실제 서비스를 위해 inference를 할 때 각 문장들의 embedding을 미리 계산해둘 수 있다는 장점이 있습니다. 이는 Inference 섹션에서 자세히 다루겠습니다.
Cross-encoder
- Cross Encoder는 일반적인 BERT의 방법론과 유사합니다. Figure 1 (b)에서 볼 수 있듯이, $ctxt$와 $cand$를 이어 붙여서 하나의 Encoder를 태우고 regression을 통해서 다음 문장으로 적절한 가에 대한 점수를 계산합니다.
- Bi-encoder와 달리 인코딩 과정에서 context와 candidate 간의 self-attention을 적용할 수 있기 때문에 둘 간의 관계를 훨씬 깊게 파악할 수 있다는 장점이 있고, 성능 역시 보통 Bi-encoder 방식에 비해 더 좋습니다.
- 학습은 위의 Bi-encoder와 마찬가지로 batch 내의 샘플을 이용하여 cross entropy loss를 최소화시키는 방식입니다.
Poly-encoder
- 논문에서 제안하는 Poly-encoder는 Bi-encoder와 Cross-encoder의 장점을 살리고 단점을 보완하고자 합니다.
- 구조는 Figure 1 (c)와 같으며, Bi-encoder처럼 context와 candidate를 독립적으로 인코딩합니다.
- Bi-encoder와의 차이점은 Context Encoder의 위에 있는 구조들인데 하나씩 살펴보겠습니다.
-
기존에는 Context Encoder의 output을 $red(\cdot)$을 통해 바로 하나의 벡터로 합쳤지만, Poly-encodeer는 code vector와의 attention을 통해서 여러 개의 벡터를 만들어냅니다. (Candidate Encoder는 기존과 동일합니다.)
\[y_{ctxt}^i = \sum_j w_j^{c_i} h_j, \quad \text{where} \quad (w_1^{c_i}, ..., w_N^{c_i}) = \text{softmax}(c_i \cdot h_1, ..., c_i \cdot h_N)\] - 이때 code vector는 일종의 latent variable이라고 볼 수 있으며, 학습 초기에는 random initialize 되고 학습 과정 중에 learnable parameter로써 함께 학습됩니다.
- Code vector는 의미적으로 해석해봤을 때, context의 여러 의미를 포착하는 역할을 한다고 볼 수 있을 것 같습니다.
-
이렇게 얻어진 벡터들(Figure 1 (c)에서 Emb 1 ~ Emb m)에 대해서 Candidate Embedding과의 attention을 통해서 한 번 더 벡터들을 합치고 최종 Context Embedding을 구합니다.
\[y_{ctxt} = \sum_i w_i y_{ctxt}^i, \quad \text{where} \quad (w_1, ..., w_m) = \text{softmax}(y_{cand_i} \cdot y_{ctxt}^1, ..., y_{cand_i} \cdot y_{ctxt}^m)\] - 최종 score는 위에서 구한 Context Embedding과 Candidate Embedding의 내적을 통해서 계산합니다.
-
- 이렇게 하면, Cross-encoder처럼 context와 candidate 간의 관계를 보다 깊게 파악할 수 있으면서, Bi-encoder처럼 문장들의 Embedding을 일정 부분 미리 계산할 수 있어서 inference 상황에서 매우 빠르고 효과적입니다.
Inference
- 실제 서비스에서는 수백, 수천만개의 후보 문장들 중에서 다음에 오기 적절할 문장을 inference를 통해서 찾아야 합니다.
- 이때, Bi-encoder 방식은 inference speed가 매우 빠르다는 장점이 있습니다.
- 후보 문장이 아무리 많아도 미리 인코딩을 해서 문장 별 Candidate Embedding을 계산해둘 수 있기 때문입니다.
- 그러면, query로 들어오는 context만 딱 한 번 인코딩해서 Context Embedding을 계산하고 미리 계산해 둔 수백, 수천만 개의 Candidate Embedding과 내적 계산만 하면 되는 것입니다.
- Transformer Encoder를 inference 하는 비용에 비하면 두 벡터의 내적 계산은 매우 빠르기 때문에 인코딩을 최대한 안하는 게 속도 향상의 포인트입니다.
- 반면, Cross-encoder 방식은 사실상 실제 서비스에서는 사용할 수 없을 정도로 느립니다.
- Cross-encoder는 context와 candidate의 쌍에 대한 계산을 하기 때문에 context가 주어지지 않으면 어떠한 계산도 미리 할 수가 없습니다.
- Query로 context가 들어오면 그때부터 context와 각 candidate를 쌍으로 인코딩하여 다음에 올 문장으로 적절한지를 계산해야 합니다.
- 즉, 하나의 query를 처리하려면 Transformer Encoder의 inference를 수백, 수천만번 진행해야 하는 것입니다. 이는 사실상 불가능하죠.
- Poly-encoder는 둘의 장점을 적절히 취하고자 합니다.
- Context와 candidate은 독립적으로 Transformer Encoder를 타기 때문에 Candidate Embedding을 미리 계산하여 구해둘 수 있습니다.
- 실제로 query로 들어온 context에 대해서 한 번 inference를 하고, 미리 계산해 둔 Candidate Embedding들에 대해서 attention만 몇 번해서 최종 score를 계산할 수 있습니다.
- 당연히 attention을 몇 번 더 하기 때문에 Bi-encoder 보다는 느리지만 그리 연산량이 많지 않아서 감수할만 합니다.
- 속도에 손해를 본 대신에 정확도 면에서 이득을 볼 수 있습니다.
- Bi-encoder와 달리 최종 score 계산 전에 context와 candidate을 아우르는 attention 연산을 하기 때문에 둘의 관계를 좀 더 잘 이해할 수 있게 되고, 당연히 보다 적절한 다음 문장을 찾을 수 있게 됩니다.
- 이렇게 Bi-encoder의 장점인 inference 속도와 Cross-encoder의 장점인 정확도를 적절히 갖춘 것입니다.
Experiments
- 앞서 소개한 ConvAI2, DSTC7, Ubuntu v2 등의 데이터에 대해서 실험을 진행한 결과는 다음과 같습니다.
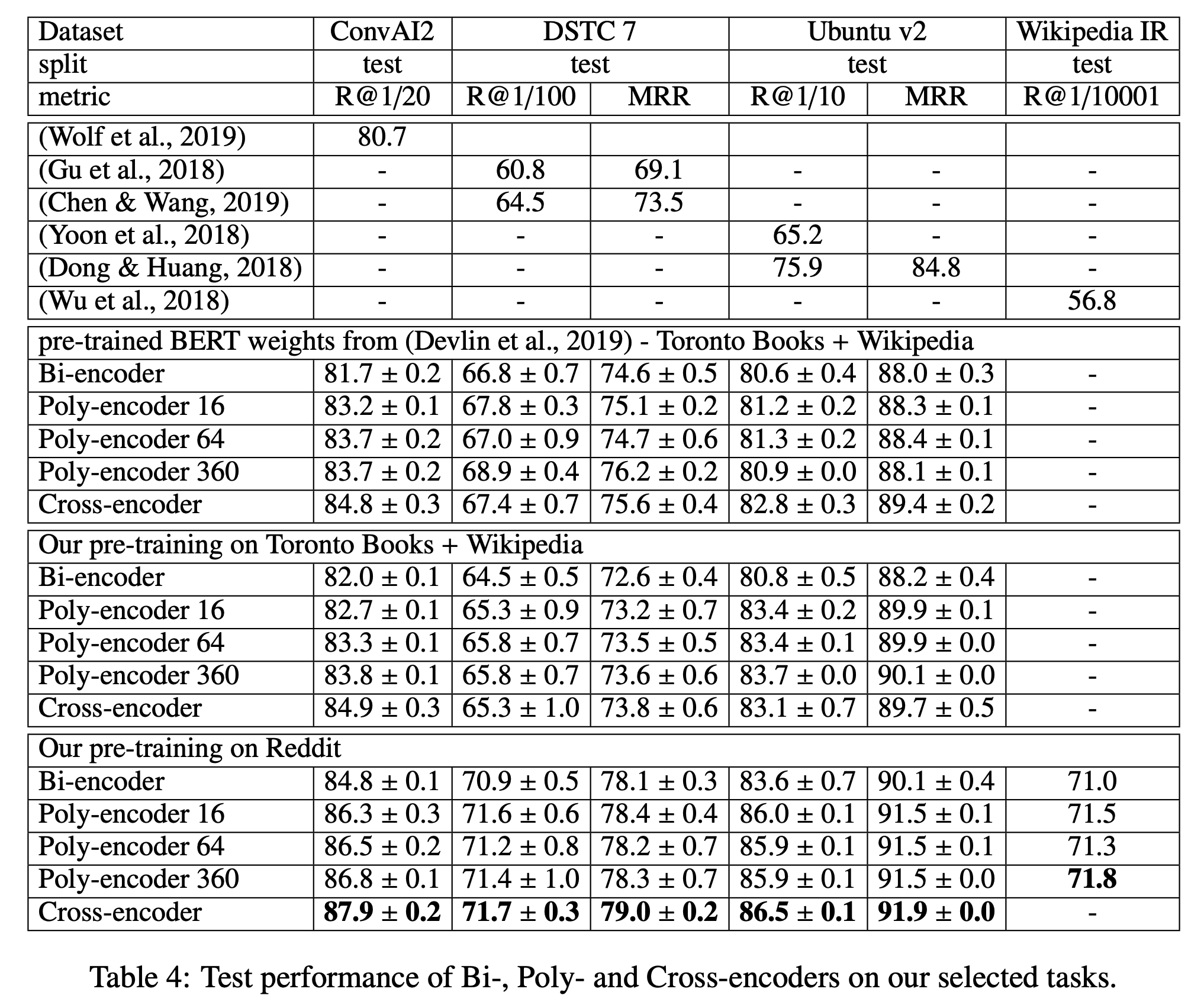
- Poly-encoder는 Bi-encoder 보다는 좋고 Cross-encoder에는 못미치는 성능을 보였습니다.

- 그리고 위의 소개한 모델은 모두 batch 내의 샘플을 negative로 활용하여 학습을 하는데, batch size가 클수록 성능이 향상되는 결과를 얻었습니다.
- 많은 negative들 속에서 진짜 positive를 찾는 것이 더 어렵기 때문에, batch size의 크기를 키워서 negative의 수를 늘릴수록 모델을 더 효과적으로 학습시킬 수 있었던 것 같습니다.
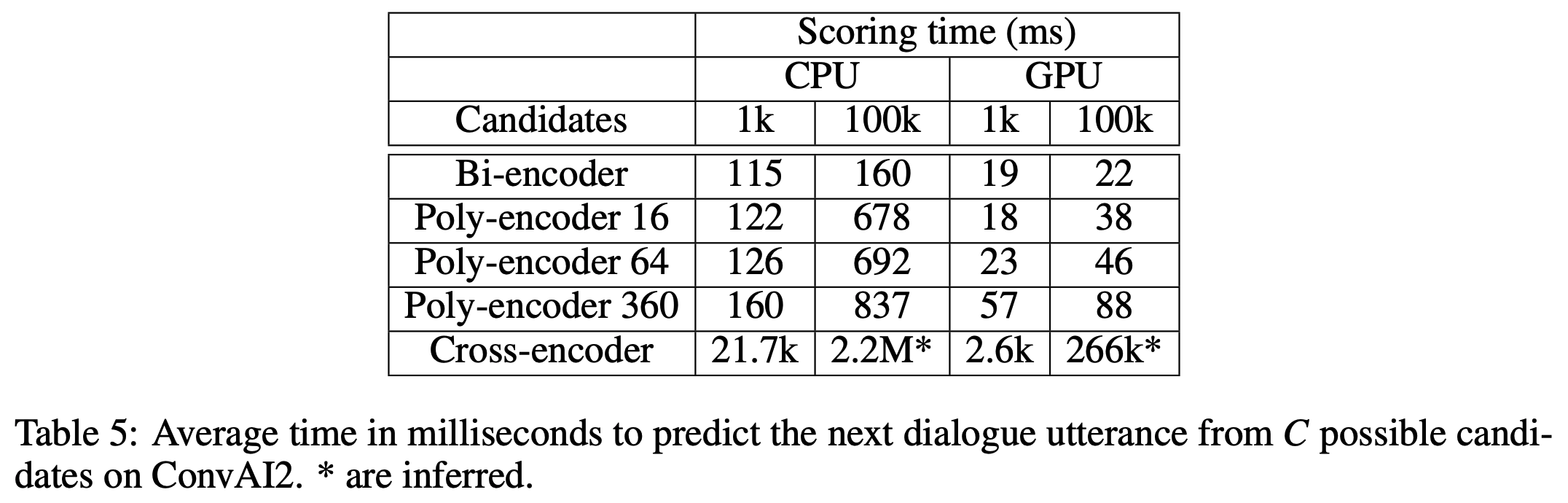
- 위의 표는 각 모델들을 CPU와 GPU 환경에서 inference 했을 때 걸리는 시간을 측정한 것입니다.
- Bi-encoder가 가장 빠른 것을 볼 수 있고 Poly-encoder도 이와 비슷하게 빠른 것을 볼 수 있습니다.
- Cross-encoder는 이 둘에 비해서 말도 안되게 오랜 시간이 걸립니다. 따라서 Cross-encoder 방식으로 query에 대한 문장을 검색하는 서비스 만드는 것은 현실적으로 어려울 것으로 보입니다.
Conclusion
- 기존의 Bi-encoder와 Cross-encoder의 한계를 극복하는 Poly-encoder를 제안함
- 여러 태스크에 대해서 Bi-encoder 보다 좋은 state-of-the-art 성능을 얻음
- Bi-encoder의 inference 속도에 가까운 빠른 inference 속도를 보이며 실제 서비스에 대한 활용 가능성을 보임

Joohong Lee
Machine Learning Researcher