Generalization through Memorization: Nearest Neighbor Language Models (ICLR 2020)
- 9 mins- Paper Link: https://arxiv.org/abs/1911.00172
- Author
- Urvashi Khandelwal, Omer Levy, Dan Jurafsky, Luke Zettlemoyer, and Mike Lewis
- Stanford University & Facebook
- Published at
- ICLR 2020
Abstract
- $k$-nearest neighbors($k$NN) 모델을 통한 pre-trained neural language model(LM)인 $k$NN-LMs를 제안함
- Nearest neighbors는 LM 학습데이터에 있는 text 데이터에 대해 pre-trained LM embedding space 상의 거리에 따라 계산됨
- 이 $k$NN 기반의 augmentation 기법을 WikiText-103 LM을 적용하였고 state-of-the-art perplexity of 15.79를 기록하였다. 이는 2.9 point 향상이며 추가 학습은 하지 않음
- Large training set에 대해서도 효율적으로 scaling up이 되고, domain adaptation도 효과적으로 이루어짐. 역시 추가 학습은 필요 없음
- 정성적으로 보았을 때, factual knowledge 같은 희귀한 패턴을 예측하는데 상당히 도움이 됨
- 이와 함께, 이런 실험 결과들을 통해 다음 단어를 예측하는 것보다 sequence of text에 대한 similarity를 학습하는 게 더 쉽고, nearest neighbor search가 long tail 패턴에 대한 Language modeling에 효과적이라는 것을 알 수 있음
1. Introduction
- LM는 전형적으로 다음의 두가지 subproblems을 품
- sentence prefix를 fixed-sized representation에 매핑시키는 문제
- 이 representation을 사용해서 다음 단어를 예측하는 문제
- “Representation learning 문제가 다음 단어 예측 문제보다 더 쉽다”는 가정 하에 새로운 language modeling approach를 제안함
- 기존 LM의 prefix embedding을 사용해서 LM이 첫번째 문제를 더 잘한다는 강력한 증거를 제시함
- (이하 Abatract의 내용과 같음)
2. Nearest Neighbor Language modeling
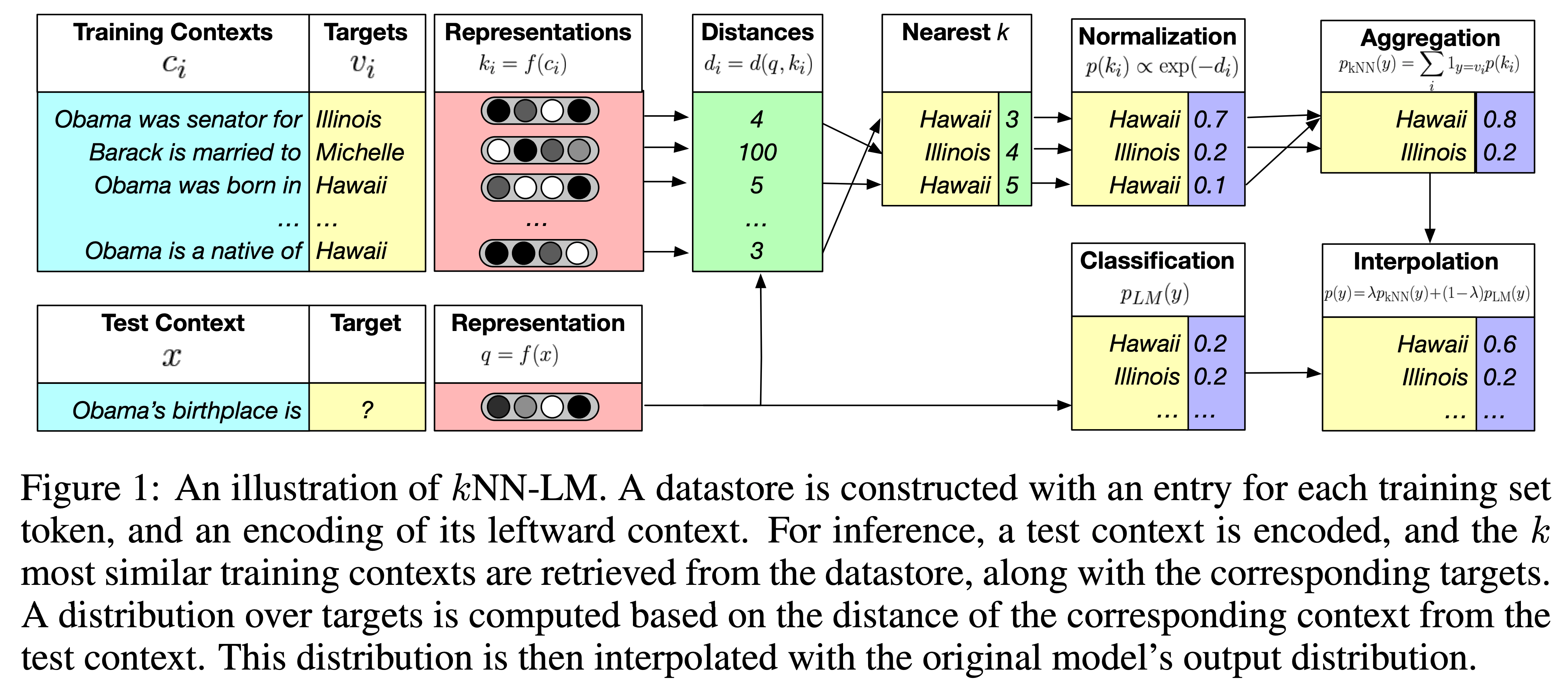
-
LM은 기본적으로 주어진 context sequence of tokens $c_t = (w_1, …, w_{t-1})$에 대해서 다음에 올 target token인 $w_t$에 대한 분포 $p(w_t c_t)$를 예측함 - 간단히 $k$NN-LM은 pre-trained LM에 nearest neighbors retrieval mechanism을 더한 형태로서 추가적인 학습은 하지 않음
- *context-target 쌍은 **inference 시에 사용할 key-value datastore에 저장함 (Figure 1 참고)
Datastore
- $f(\cdot)$는 어떤 context $c$를 pre-trained LM을 이용해서 fixed-length vector representation으로 매핑해주는 함수임
- $i$-th training example $(c_i, w_i) \in \mathcal{D}$에 대해서 key-value 쌍을 $(k_i, v_i)$ 만듬. 여기서 $k_i$는 context representation $f(c_i)$가 되고, $v_i$는 target word $w_i$가 됨
- 최종적으로 datastore $(\mathcal{K}, \mathcal{V})$는 $\mathcal{D}$에 있는 모든 training examples로 만든 모든 key-value 쌍이 되고, 다음과 같은 수식으로 나타낼 수 있음:
Inference
-
일단 주어진 input context $x$에 대해서 모델은 다음 단어에 대한 distribution $p_{LM}(y x)$와 context representation $f(x)$를 만들어냄 - 여기서 모델은 datastore에 $f(x)$에 대한 $k$-nearest neighbors $\mathcal{N}$을 검색 쿼리로 던짐 (검색은 distance function $d(\cdot, \cdot)$을 따르며 논문의 실험에서는 $L^2$를 사용)
- 그렇게 얻어낸 nearest neighbor $\mathcal{N}$에 대해서 negative distance에 대한 softmax를 기반으로 neighbor에 대한 distribution을 구함. 검색된 target이 중복될 경우 이들의 softmax probability을 aggregating함
- 최종적으로 기존 $p_{\text{LM}}$과 $p_{\text{kNN}}$ distribution을 tuned parameter $\lambda$를 사용해 interpolation하여 다음의 최종 $k$NN-LM의 distribution을 만들어냄:
Implementation
- Datastore은 billions 단위의 examples을 다뤄야 함
- 이런 대용량의 datastore에 대한 검색을 위해 FAISS (Johnson et al., 2017)을 사용함
- FAISS는 high-dimensional vector space에 대해 빠르고 memory-efficient 하게 nearest neighbor를 검색할 수 있는 라이브러리임
- 뒤에 실험 파트에서 나오지만 distance metric으로 $L^2$를 썼을 때가 inner product를 썼을 때보다 더 좋았음
3. Experimental Setup
Data
- WikiText-103: standard benchmark by Merity et al. (2017) for autoregressive language modeling. training 103M tokens, devset & testset 250K, respectively
- Books: Toronto Books Cropus (Zhu et al., 2015). 0.7B tokens
- Wiki-3B: English Wikipedia. 2.87B tokens
- Wiki-100M: random 100M token subset of Wiki-3B
- WikiText-103을 제외하고는 모두 BPE를 사용
Model Architecture
- LM으로 Transformer (Vaswani et al., 2017) Decoder를 사용함
- Baevski & Auli (2019)에서 설명한 정확한 구조와 optimization을 따랐음
- 구조: Transformer Decoder + sinusoidal position embedding and stack 16 block (자세한 내용은 해당 논문의 Section 4.1 참고)
- Optimization: Nesterov’s accelerated gradient method (Sutskever et al., 2013)을 사용 (자세한 내용은 해당 논문의 Section 4.5를 참고)
- This model consists of 16 layers, each with 16 self-attention heads, 1024 dimensional hidden states, and 4096 demensional feedforward layers, amounting to 247M trainalble parameters.
- Adaptive inputs (Baevski & Auli, 2019)과 adaptive softmax (Grave et al., 2017b) with tied weights (Press & Wolf, 2017)을 적용하였음
- WikiText-103에만 적용하고 나머지 데이터셋에는 적용하지 않음
Evaluation
- Trained to minimize the negative log-likelihood of the training corpus
- Evaluated by perplexity (exponentiated negative log-likelihood) on held out data
- 최대 2560 tokens (in WikiText-103) 을 extra prior context로 주어지고 각 test example 별로 512 tokens에 대해서 ppl scoring을 함. 다른 데이터셋에 대해서는 512 tokens을 extra prior context로 줌
$k$NN-LM
- Sentence prefix의 representation이자 $k$NN-LM의 datastore에 사용할 key는 1024-dimensional representation이며, Transformer LM의 final layer에서 feed forward network에 들어가기 전 hidden vector를 사용함 (after self-attention and layernorm; Section 5에서 자세히 설명)
- 학습된 LM로 training set에 대해 single forwarding 하고 이를 datastore의 key(vector), value(next word)로서 활용함
- Forwarding할 때, 각 target token에 대해 WikiText-103는 최소 1536 tokens이 prior context를 제공하였고, 이외의 데이터셋은 512 tokens을 제공함
- FAISS
- Index는 1M 개의 randomly sampled key를 사용하여 4096개의 cluster centroid를 학습시켜서 만듬
- 효율을 위해 key(vector)는 64-bytes로 quantization함. 다만 WikiText-103은 full precision을 사용
- Inference 시에 $k=1024$ neighbors를 검색하고 최대 32개의 cluster centroid만을 보도록 제한함
- Distance metric은 $L^2$를 사용함
- Interpolation parameter $\lambda$는 validation set으로 tuning함
Computational Cost
- 아무리 $k$NN-LM이 추가 학습 없이 기존 LM을 쓸 수 있다고는 하지만 일단 key, value를 저장하기 위해 학습 데이터를 1번 forwarding 해야 하고, 이는 약 1 epoch 정도 학습하는 비용이 듬
- 그리고 저장해둔 key를 FAISS에 올리는데(build) single CPU 기준으로 대략 2시간 정도 걸림
- 최종적으로 validation set에 대해 1024개의 nearest key를 검색하는데 약 25분 걸림
- Large cache를 build 하는 비용은 샘플 수에 따라서 선형적으로 증가하지만, 병렬처리가 쉽고 GPU 기반의 학습이 필요 없음
4. Experiments
4.1. Using the Training Data as the Datastore
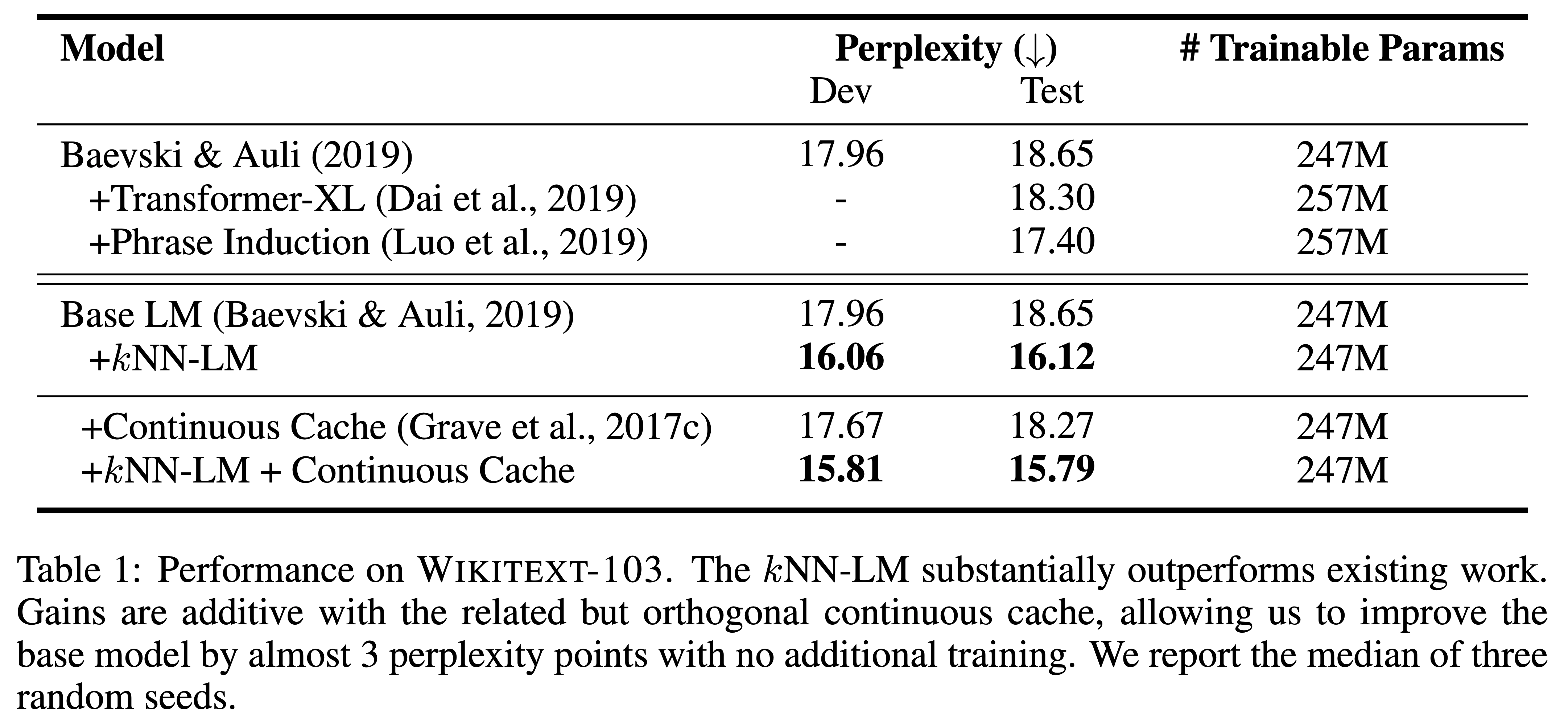

- 첫 번째 실험으로 LM을 학습시킨 데이터를 그대로 활용해서 datastore를 만든 경우를 봄
- WikiText-103 데이터에 대해서 nearest neighbor mechanism을 더했을 때 성능이 향상되었고 new state-of-the-art를 기록한 것을 Table 1을 통해 볼 수 있음
- 백과사전식의 Wikipedia가 캐싱에 있어서 유리한 점이 있을 수도 있어서 Books 코퍼스로도 동일한 실험을 진행하였고, 역시 SOTA 성능을 기록하였음 (Table 2)
4.2. More Data without Training
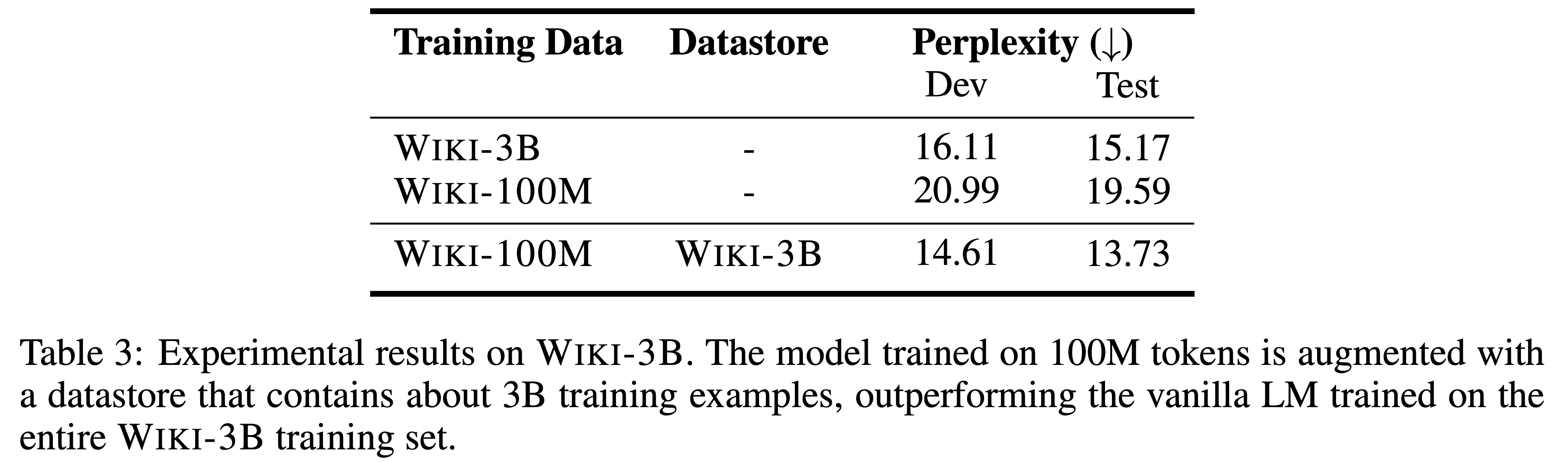
- LM의 학습 데이터와 다른 데이터셋으로 datastore를 build해도 똑같이 향상이 있을지에 대한 실험을 진행
- training LM: Wiki-100M
- Building datastore: Wiki-3B (larger than the training set)
- 위 세팅으로 학습한 $k$NN-LM을 Wiki-3B로만 학습한 vanilla LM과 비교
- Table 3을 보면 성능이 매우 향상된다는 것을 볼 수 있음
- 당연히 Wiki-3B로 학습한 LM이 Wiki-100M으로 학습한 LM 보다 성능이 좋았고 이에 대해 retrieval을 붙이면 성능이 더욱 향상됨
- 이 결과로 미루어보아, LM의 학습 데이터를 키우는 것보다 작은 데이터셋으로 representation을 학습하고 large corpus에 대한 $k$NN-LM으로 augmentation을 하는 게 더 좋다고 할 수 있음
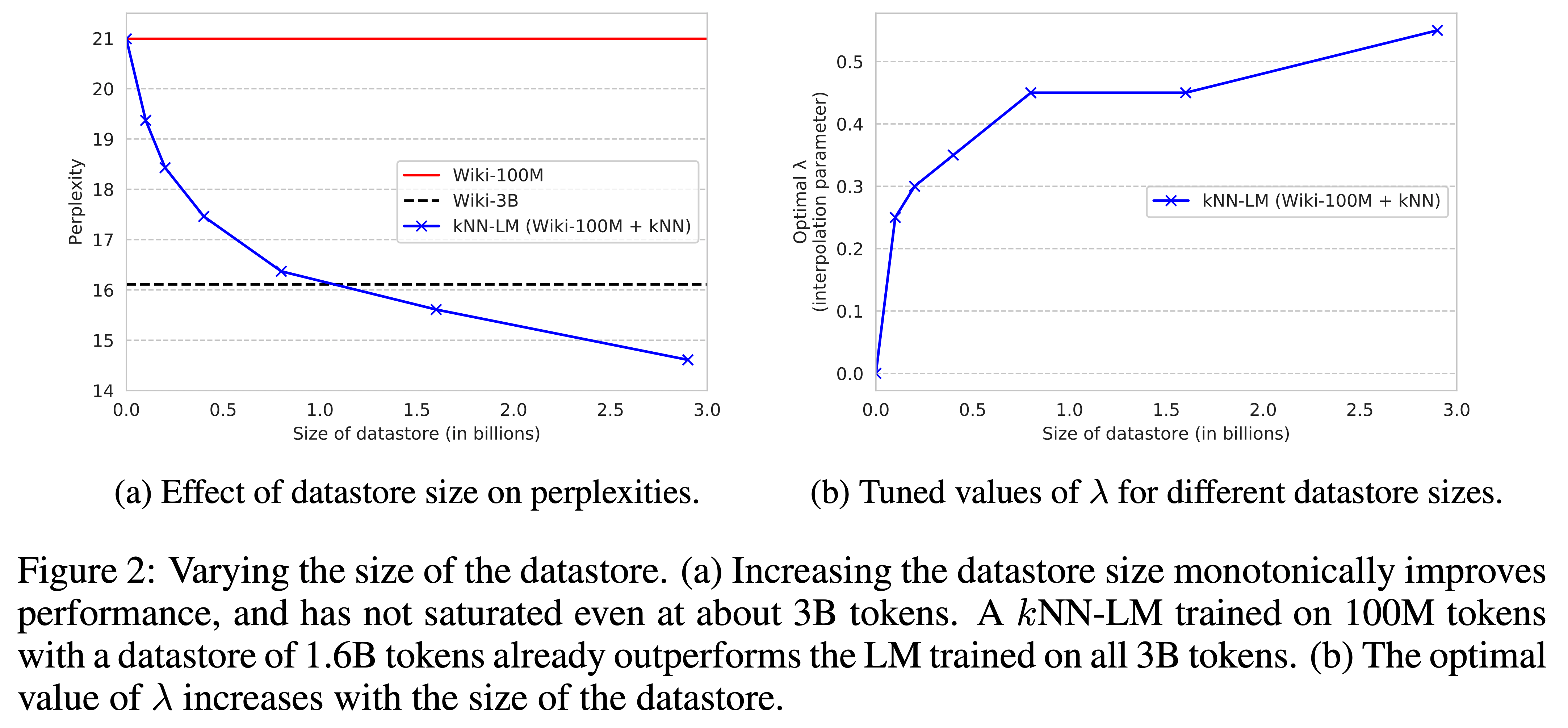
- $k$NN retrieval을 위한 데이터 양이 성능에 얼마나 영향을 주는지 알아보기 위해서 Wiki-3B 데이터를 샘플링하여 실험을 해보았고, 결과는 Figure 2a와 같았음
- 1.6B만 썼을 때 이미 Wiki-3B로 fully 학습한 모델보다 성능이 좋았고, 3B를 다 써도 성능이 saturate되지 않는 것으로 보아 데이터 크기를 더 키우면 더 성능이 향상될 것으로 보임
- Figure 2b는 datastore의 크기가 커질수록 $k$NN component에 더 의지($\lambda$)한다는 것을 보임
4.3. Domain Adaptation
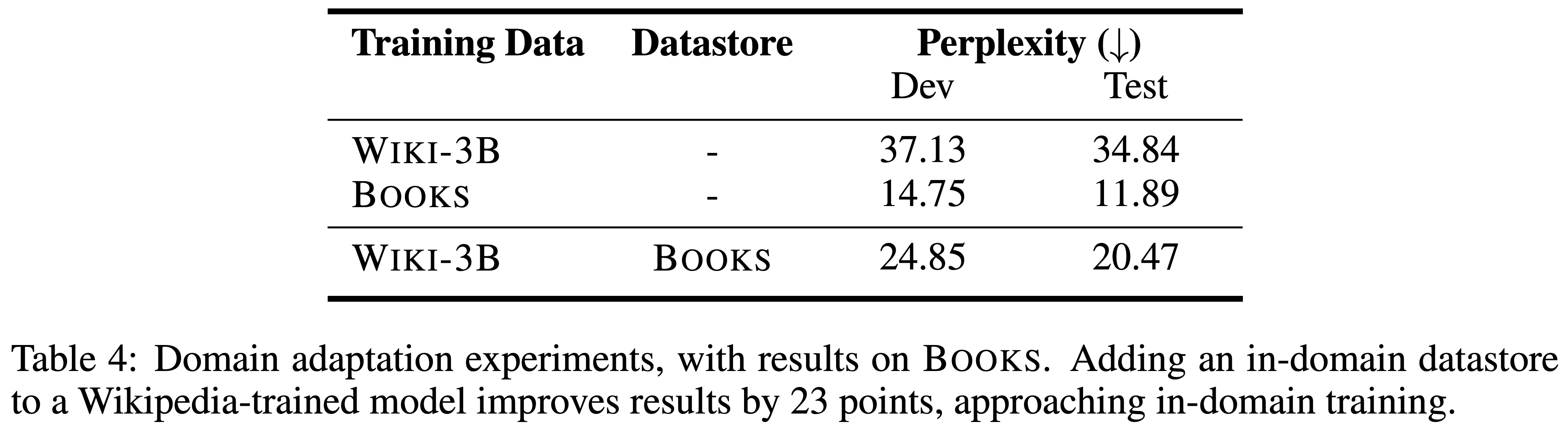
- Domain adaptation 성능을 보이기 위해, Wiki-3B로 학습한 LM에 대해서 Books 코퍼스에 대해서 test(inference)하는 실험을 함
- 기본적으로 그냥 하면 성능이 상당히 떨어짐
- 이때 Books 코퍼스로 만든 datastore를 붙이면 성능이 상당히 개선되는 것을 볼 수 있음
- 즉, target domain에 대한 코퍼스만 있으면 해당 코퍼스에 대해 새로 LM을 학습시키지 않아도 충분히 domain adaptation이 가능하다고 볼 수 있음
5. Tuning Nearest Neighbor Search
Key Function
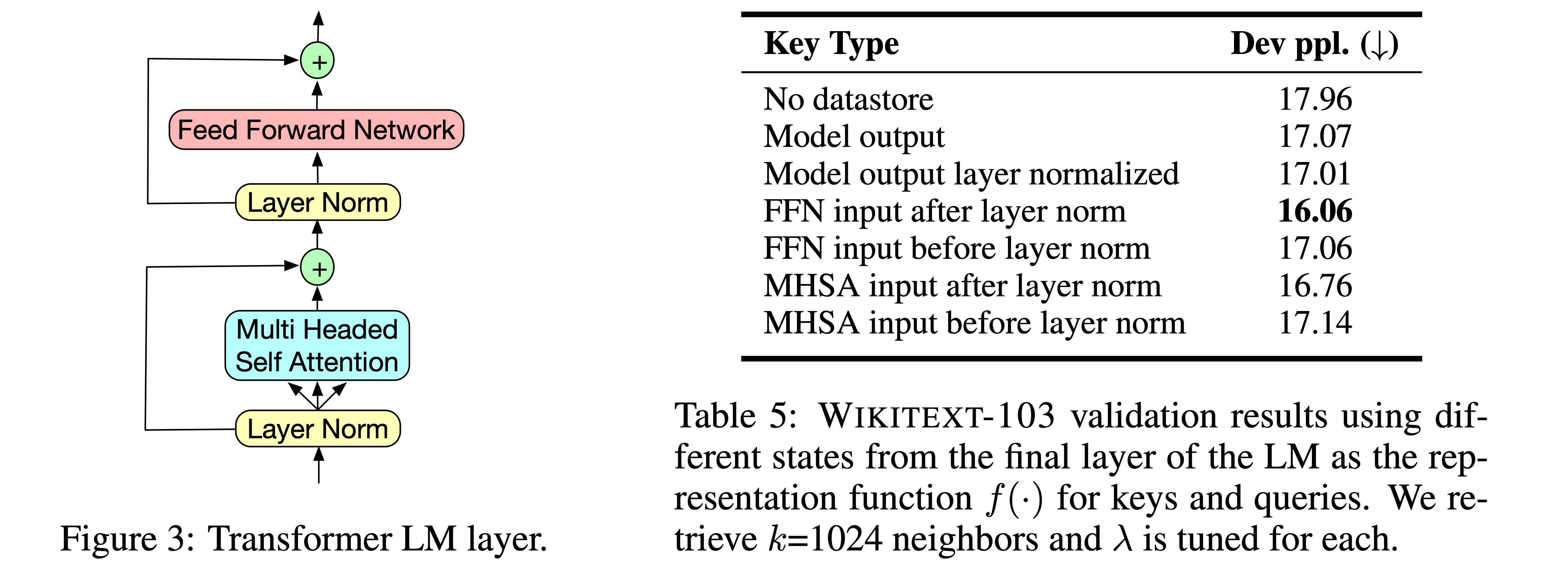
- Retrieval을 위해 Context $c$의 representation을 어떻게 뽑을지에 대한 실험
- 기본적으로 LM의 intermediate state $f(c)$를 통해 추출함
- Transformer LM의 각 layer는 Figure 3처럼 생겼음. Table 5는 LM layer의 각 세부 layer를 representation으로 썼을 때 성능을 보임
- FFNN 전 Layer Norm 후의 vector를 prefix의 representation으로 썼을 때, $k$NN-LM의 성능이 가장 좋았음
- 이런 결과로 미루어보아, FFNN 전의 self-attention만 탔을 때가 representation으로는 더 좋고, FFNN 후는 다음 단어 prediction을 위해 좀 더 피팅되어있지 않나 싶음
- Second-last layer에 대해서도 실험해봤는데, 살짝 안좋았음
Number of Neighbors per Query
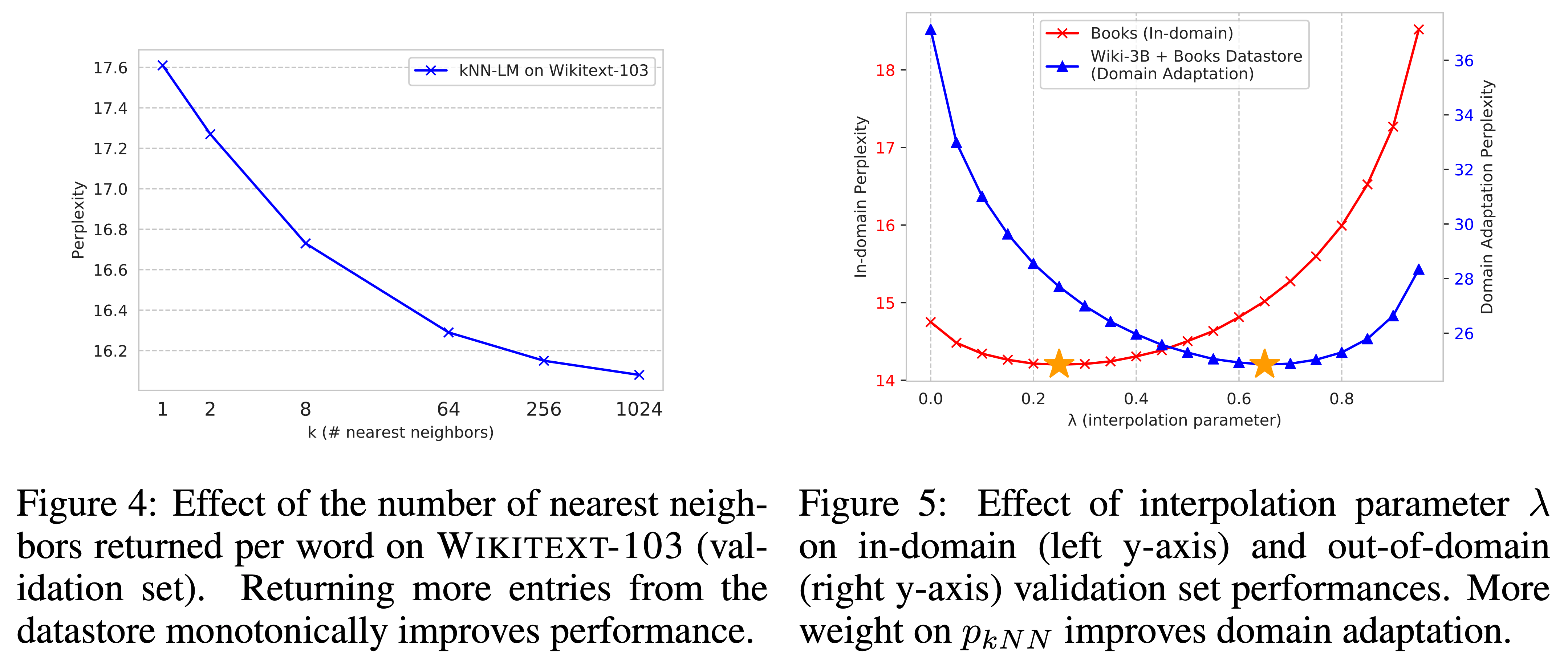
- Nearest neighbor의 수 $k$에 대한 실험
- $k$가 클수록 성능이 계속 좋아짐
- 근데 $k$가 8로 작아도 이미 SOTA임
Interpolation parameter
- LM의 distribution과 $k$NN search의 distribution을 interpolation하는 parameter $\lambda$에 대한 실험
- 결과는 Figure 5와 같음
Precision of Similarity Function
- FAISS에서 quantization을 한 것보다 full precision으로 했을 때 성능이 올랐음 (16.5 -> 16.06)
6. Analysis
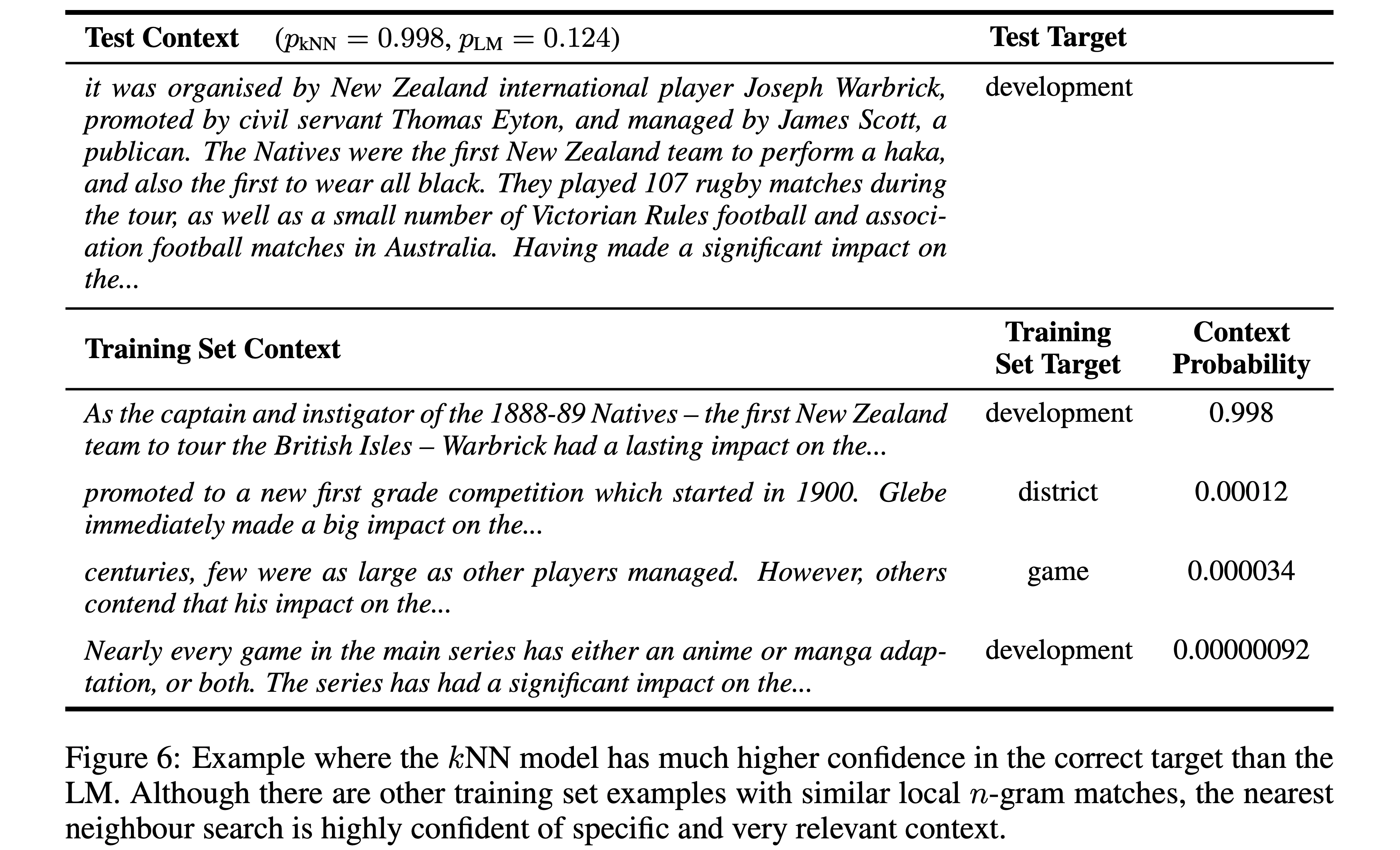
Qualitative Analysis
- $k$NN-LM이 왜 좋은지 이해하려고 $p_{\text{KNN}}$가 $p_{\text{LM}}$ 보다 나은 경우를 확인해봄
- Figure 6과 Appendix A가 이에 해당하는 예시임
- 주로 사실적 지식이나 이름, training set에 거의 비슷하게 존재하는 패턴 등 희귀한 패턴에 대해서 굉장히 잘한다는 사실을 알 수 있었음
- 이런 예시를 통해서 Similar representation을 만들어서 explicit하게 nearest neighbor를 찾는 것이 model parameter를 통해 implicit하게 다음 단어를 기억하는 것보다 쉽다고 볼 수 있음
Simple vs Neural Representation
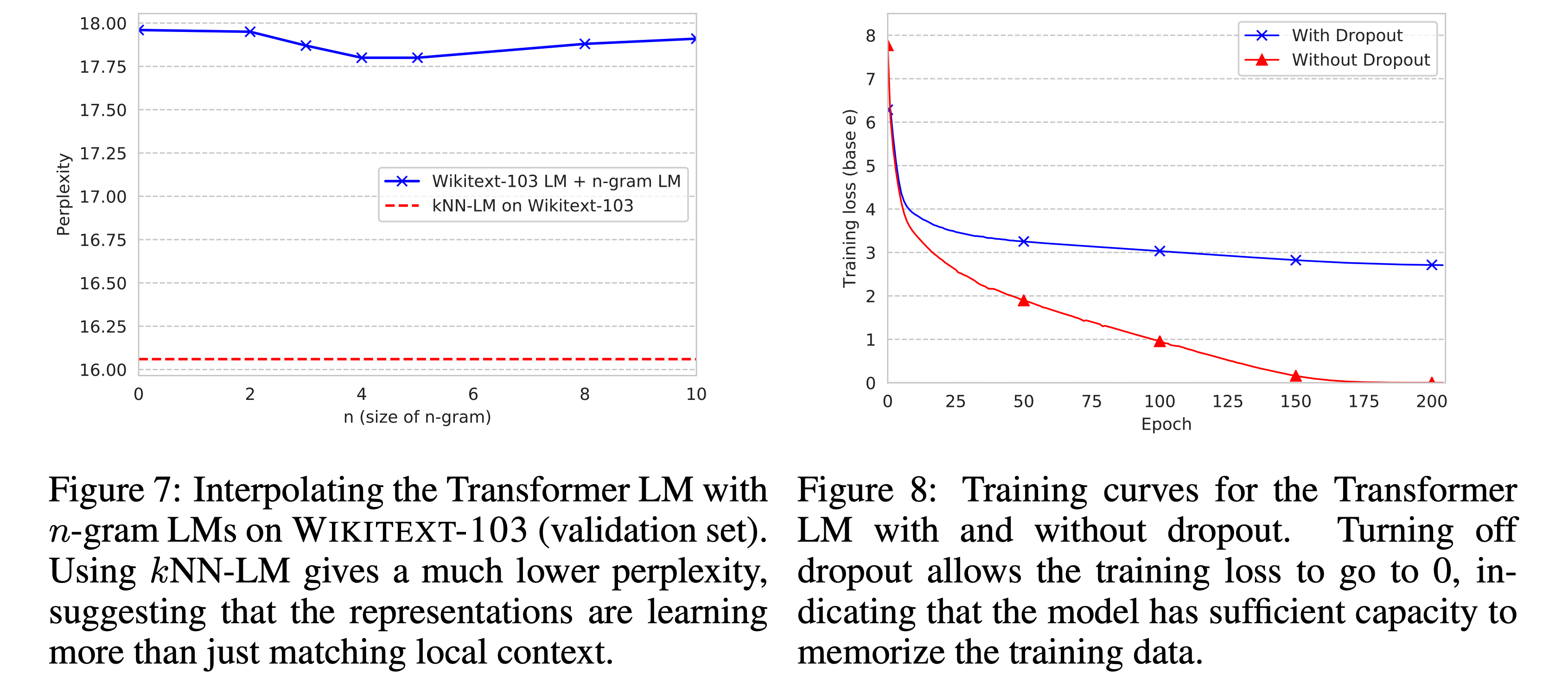
- Long-tail 현상이 주로 희귀한 $n$-gram 패턴(이름 등)에서 자주 나온다는 것을 알게 됨
- 그러면 $k$NN 대신에 그냥 $n$-gram LM을 쓰면 똑같이 성능이 향상되지 않을까? 라는 생각을 해봄
- $n$-gram LM에 대한 실험을 Figure 7과 같이 해보았고, 결과적으로 약간의 성능 향상은 있었지만 $k$NN이 더 좋았음
Implicit vs Explicit memory
- Neural network parameter가 implicit하게 training dataset을 외워버린다면, explicit한 datastore를 대체할 수 있을까?에 대한 실험
- 1단계:
- 일단 모델이 training dataset을 완전히 외울 수 있는지 보기 위해 dropout을 제거해서 overfitting을 시켜보았고, 결과는 Figure 8처럼 loss가 0에 수렴하면서 training set을 완전히 외우는 게 가능함
- 다만 overfitting이 되었기에 devset에 대한 성능은 28.59로 dropout을 써서 generalize한 LM의 17.96보다 별로임
- 그래도 일단 결과적으로 Transformer가 training set을 외울 정도의 충분한 capacity는 갖고 있다는 것을 확인함
- 2단계:
- 이제 nearest neighbor 대신에 training set을 외운 LM(memorizing LM)을 써서 original LM과 interpolation을 해봄
- 결과
- Original LM만 썼을 때보다 0.1 정도 성능 향상을 시켜주지만, $k$NN-LM은 1.9의 향상을 시켜줌
- 결과로 미루어보아, training example을 다 외울지라도 context representation이 충분히 generalization이 되지는 않은 것으로 보임
- 1단계:
- 왜 $k$NN-LM이 성능을 향상시킬까? (추측)
- Transformer LM이 simliarity 관점에서 효과적인 represenation를 잘 학습함
- Transformer가 training set을 외우기에 충분한 capacity를 갖고 있지만 그냥 다 외워버리면 generalization 관점에서 덜 효과적임.
- 하지만 $k$NN-LM은 모델이 효과적인 similarity function을 학습하면서도 training set을 외움
7. Related Work
- pass
8. Conclusion and Future Work
- Test time에 training example을 직접적으로 활용하며 기존 standart LM 보다 상당히 성능 개선을 한 $k$NN-LMs을 제안함
- 이 approach는 어떤 neural LM에도 적용이 가능함
- 이게 잘 되는 이유는 contexts 간의 similarity function을 학습하는 게 주어진 context에 대해 다음 단어를 예측하는 것보다 쉽기 때문이라고 봄
- Future work으로 similarity function을 학습시키는 방법에 대한 탐구와 datastore를 줄이는 방법을 생각 중임

Joohong Lee
Machine Learning Researcher