MoEL: Mixture of Empathetic Listeners (EMNLP 2019)
- 7 mins- Paper Link: https://www.aclweb.org/anthology/D19-1012/
- Author
- Zhaojiang Lin, Andrea Madotto, Jamin Shin, Peng Xu, Pascale Fung
- The Hong Kong University of Science and Technology
- published at
- EMNLP 2019
- Key Points and My Comments
- 이전 연구는 현재 발화의 감정 상태를 예측하는 것과 decoding 하는 문제를 멀티 태스크로 푸는 방향이 하나가 있고 (EmpatheticDialogue), 고정된 감정을 갖는 발화를 생성하는 방향이 있음 (PersonaChat)
- 이 두 어프로치는 몇 가지 중요한 포인트를 놓치고 있는데, 1) 어떤 감정으로 대답해야 하는지 implicit하게 학습해서 interpretability의 한계와 generic response 문제가 있음. 또한 2) 조건부로 generation을 할 때 우리는 특정 감정을 인풋으로 주는데, 이때 이런 감정이 적절한 건지 우리도 사실 모른다는 문제점이 있음
Abstract
- 이전 empathetic dialogue system 연구들은 주로 주어진 특정 emotion에 대한 generation을 하는 게 메인이었음
- 그러나 empathy는 generation도 필요하지만 understanding 쪽도 중요함. 이런 이해를 바탕으로 적절한 감정의 발화를 생성해야 함
- 그래서 우리는 empathy를 모델링하는 e2e novel approach인 MoEL을 제안함
- 우리 모델은 먼저 유저의 감정을 포착하고 감정에 대한 분포를 내놓음. 그럼 이걸 기반으로 MoEL은 여러 감정 별 Listener의 output state를 soft하게 조합해서 적절한 empathetic response를 내놓음. 각 Listener는 담당하고 있는 감정에 특화되어 있음
- Empathetic dialogues (Rashkin et al., 2018)의 human evaluation을 했을 때 SOTA
- 각각 generated response를 보면 interpretable함
1. Introduction
- 대화를 위한 neural approach들이 꽤 잘 됨. 다만, MLE를 기반으로 하기에 일반적이고 반복적인 말들이 나옴
- Commonsense의 이해와 일관된 페르소나 모델링은 chatbot engaging에 도움이 됨
- Emotion 이해와 empathy도 상당히 중요하지만 지금까지는 크게 주목 받지 못했음
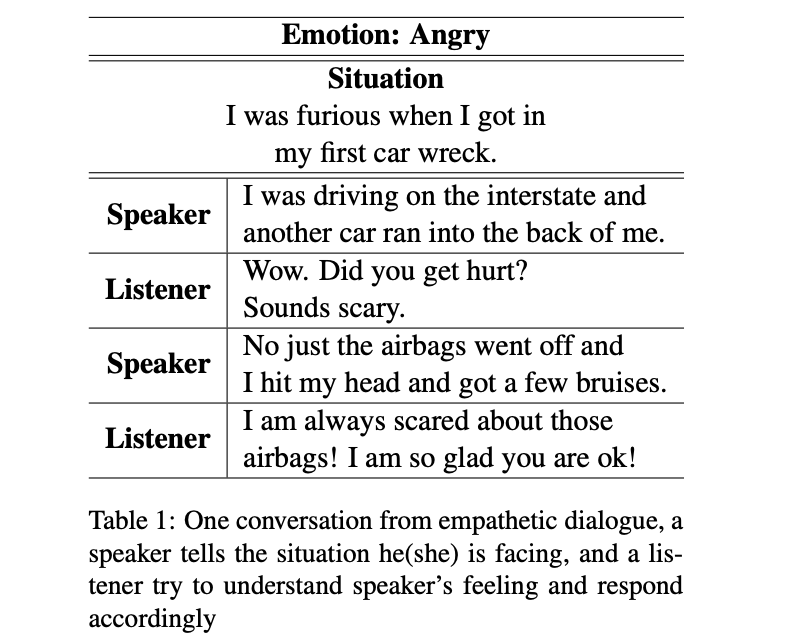
- Table1은 empathetic-dialogues dataset (Rashkin et al., 2018)의 샘플임
- 위 예시처럼 사람은 상황과 상대방의 감정에 따라 적절하게 대답을 하게 됨
- 이렇게 empathy과 emotional understanding이 중요하긴 하지만, 이렇게 적절한 emotion을 인식하고 대답하는 dialogue agent는 학습시키기가 매우 어려움
- 이 문제를 풀기 위해 지금까지 크게 2가지 방향의 연구가 있었음
- Multi-task approach
- 현재 유저 발화의 emotional state를 예측하는 문제랑 그에 적절한 response generation 문제를 multi-task로 동시에 학습
- Conditional generation with certain fixed emotion
- 특정 emotion에 대한 generation
- Multi-task approach
- 위의 두 방법은 empathetic and emotional response를 잘 생성해냄. 하지만 몇가지 중요 포인트를 놓침
- 모델이 emotion을 이해해서 implicit하게 적절한 답변에 대해 학습한다는 가정이 들어감. 하지만 추가 inductive bias가 없다면 single decoder는 interpretable하지 않고 generic한 답변만 내놓게 됨
- 생성할 때 특정 emotion이 condition이 주어진다는 가정이 들어감. 하지만 우리는 종종 empathetic response를 만들기 위해 어떤 emotion이 적절한지 모름. 따라서 불명확한 emotion을 condition으로 generation한다는 것은 이상함
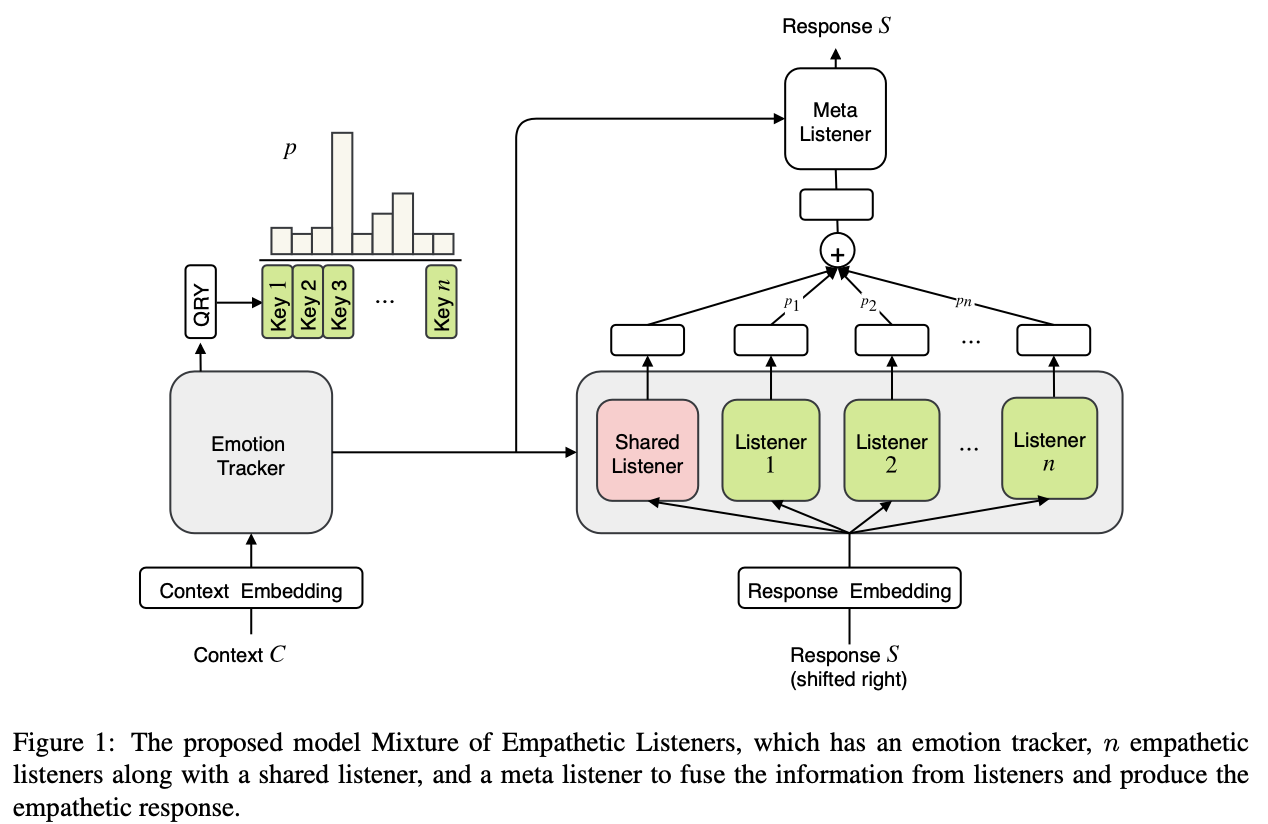
- 이런 문제를 해결하기 위해서, 우리는 Mixture of Empathetic listeners (MoEL)를 제안함
- Rashkin et al. (2018)과 유사하게 dialogue context를 인코딩해서 n개의 emotion에 대한 emotional state를 만듬
- 디코딩에서 차이점이 생기는데, 하나의 디코더를 쓰는 게 아니고 n개의 emotion 각각을 위한 디코더를 n개 둠. 이걸 우리는 이 디코더들을 listeners 라고 부르기로 함
- 이 listeners는 Meta-listener와 함께 학습됨. Meta-listener는 emotion classification의 결과 distribution을 기반으로 각 listener의 output을 softly combine함
- 이를 통해서 모델이 context of emotion에 대한 이해를 바탕으로 어떻게 적절한 리액션을 고를지 explicit하게 학습할 수 있음 (interpretability에 대한 얘기인듯)
- 성능 평가를 위해 competitive baseline들과 비교 테스트를 하였고, human evaluation도 함
- SOTA를 찍었으며, 분석을 통해서 MoEL이 효과적으로 올바른 listener에 집중하고 있다는 걸 보였으며, 또한 모델이 각 emotion에 대해 어떻게 대응하는 게 알맞는 것인지 학습함. 이런 이유로 more interpretable generative process라고 생각함
2. Related Work
3. Mixture of Empathetic Listeners
- dialog context C={U1, S1, U2, S2, …, Ut}
- speaker emotion state at each utterance Emo = {e1, e2, …, et}
- 모델은 speaker의 마지막 emotional state e_t를 예측하고 이에 적절한 empathetic response S_t를 생성해내는 것이 목표임
- MoEL은 Figure 1과 같이 크게 3가지 컴포넌트로 구성됨
- Emotion tracker: context C를 인코딩하고 user의 emotion에 대한 예측(distribution)을 함
- Emotion-aware listeners: 모든 listenser들은 독립적으로 움직이며, distribution을 기반으로 각각의 representation을 뽑음
- Meta listener: 모든 listener의 representation을 weighted-sum하고, 이를 기반으로 최종 response를 생성해냄
3.1. Embedding
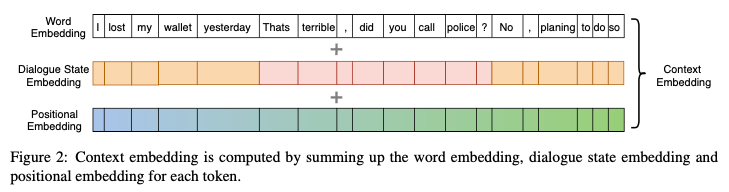
- Context embedding E^C는 word embedding E^W, positional embedding E^P, dialogue state embedding E^D의 합으로 이루어진다. dialogue state embedding은 발화자에 대한 turn embedding인 것으로 보임 (Wolf et al., 2019)
- E^C(C) = E^W(C) + E^P(C) + E^D(C)
3.2. Emtion Tracker
- 기본적으로 Transformer encoder(TRS_Enc)를 사용함
- 모든 context의 발화들은 모두 순서대로 concat함
- BERT에서의 CLS 토큰 대신에 QRY 라는 토큰을 만들어서 문장의 맨 앞에 붙임
- 최종적인 Transformer encoder로부터 얻는 context representation은 다음과 같음:
- H = TRS_Enc(E^C([QRY; C])), where [;] denotes concatenation
- 최종 QRY의 representation은 H의 첫번째 토큰의 representation인 H_0임
- 이걸 가지고 emotion distibution을 만듬 (만드는 방법은 다음 섹션에 나옴)
3.3. Emotion Aware Listeners
- Emotion-aware listeners는 크게 하나의 shared listener와 n개의 독립적인 emotion 별 listener로 이루어져있음
- shared listener: 모든 감정에 대한 shared information을 학습함
- n listeners: parameterized Transformer decoders(TRS_Dec). 특정 감정에 대한 적절한 react를 학습
- n개의 listener 각각에는 user emotion distribution을 기반으로 서로 다른 weight를 주고, shared listener는 고정된 1의 weight를 주어서 모든 감정에 대한 일반적인 학습을 하게 함
- user emotion distribution은 Key-Value Memory Network (Miler et al., 2016)을 통해서 만듬.
- 각 감정에 대한 (key, value) 쌍을 만듬. key는 random init, value는 TRS_Dec의 아웃풋
- 앞에서 구한 QRY의 representation인 H_0를 모든 key에 대해서 dot-product를 해서 softmax 취함
- 이렇게 얻어진 확률 분포를 감정에 대한 distribution p 라고 함
- p에 대해 emotion classification에 대한 cross entropy loss를 적용함
- 또한 모든 감정에 대한 TRS_Dec를 p 분포로 weighted-sum하고, shared listener는 그냥 더해줌.
- V_M = V_0 + sum{p_i * V_i}
3.4. Meta Listener
- Meta listener는 또다른 transformer decoder이며, 앞에서 encoder가 만든 H와 emotion-aware listeners가 만든 V_M에 대해서 decoding하여 최종 response를 생성함
- 이렇게 생성된 토큰(단어)들에 대해서 MLE 기반으로 학습
- 최종 loss는 앞서 구한 emotion classification loss와 generation loss의 합이며, 각각 하이퍼 파라미터 alpha, beta가 상수로 붙음
Experiment
4.1. Dataset
- Empathetic dialogues (Rashkin et al., 2018) dataset을 사용
- 25k one-to-one open-domain conversation grounded in emotional situations
- 32 emotion labels
4.2. Training
- Adam, GloVe 사용. 나머지 파라미터는 다 random initialization
4.3. Baseline
- Transformer (TRS): 그냥 MLE로 학습한 standard Transformer (Vaswani et al., 2017)
- Multitask Transformer (Multi-TRS): emotion에 대한 additional supervised information을 같이 multitask로 학습하는 Transformer (Rashkin et al., 2018)
4.4. Hyperparameter
- word embedding size: 300
- hidden size: 300
- 2 self-attention layers made up of 2 attention heads with embedding dimension 40
- positionwise feedforward with 1D conv layer with 50 filters of width 3
- batch size: 16
4.5. Evaluation Metrics
- BLEU
- Human Ratings
- Human A/B Test
5. Results
- Emotion detection

- Response evaluation
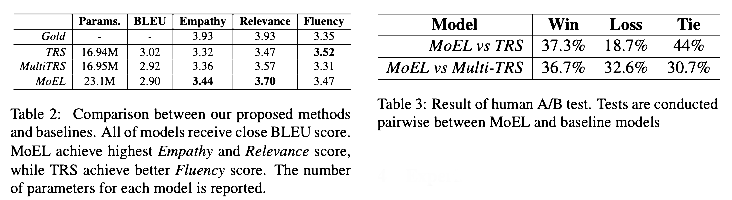
6. Analysis
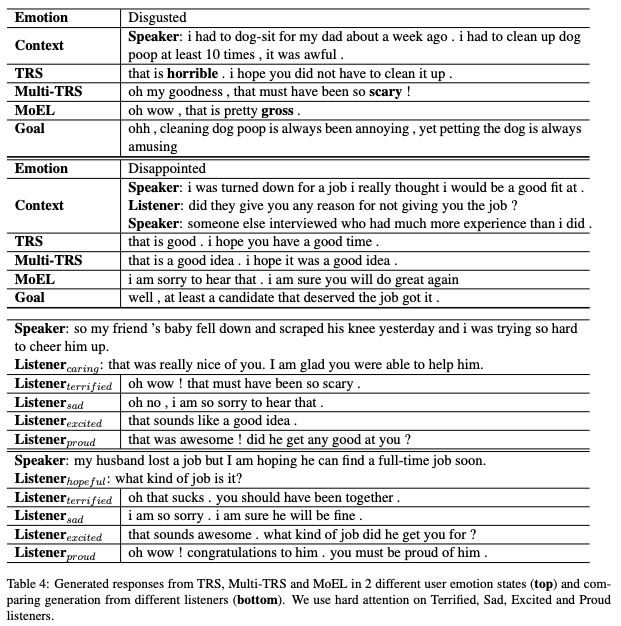
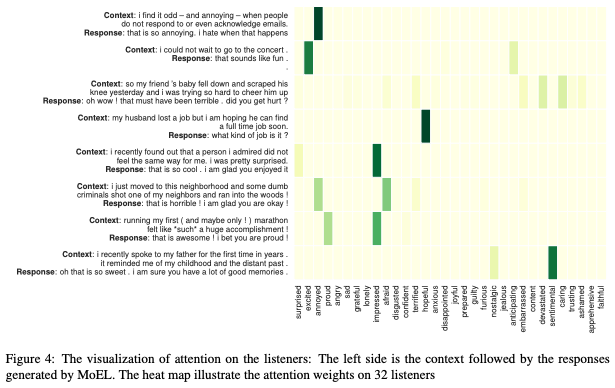
7. Conclusion & Future Work
In this paper, we propose a novel way to generate empathetic dialogue responses by using Mixture of Empathetic Listeners (MoEL). Differently from previous works, our model understand the user feelings and responds accordingly by learning specific listeners for each emotion. We benchmark our model in empathetic-dialogues dataset (Rashkin et al., 2018), which is a multiturn open-domain conversation corpus grounded on emotional situations. Our experimental results show that MoEL is able to achieve competitive performance in the task with the advantage of being more interpretable than other conventional models. Finally, we show that our model is able to automatically select the correct emotional decoder and effectively generate an empathetic response. One of the possible extensions of this work would be incorporating it with Persona (Zhang et al., 2018a) and task-oriented dialogue systems (Gao et al., 2018; Madotto et al., 2018; Wu et al., 2019, 2017, 2018a; Reddy et al., 2018; Raghu et al., 2019). Having a persona would allow the system to have more consistent and personalized responses, and combining open-domain conversations with task-oriented dialogue systems would equip the system with more engaging conversational capabilities, hence resulting in a more versatile dialogue system.

Joohong Lee
Machine Learning Researcher