Gunrock: Building A Human-Like Social Bot By Leveraging Large Scale Real User Data (Alexa Prize 2018)
- 6 mins- Paper Link: https://pdfs.semanticscholar.org/b402/b85ad45e3ac51f1da8ee718373082ce24f47.pdf]
- Author
- Chun-Yen Chen , Dian Yu , Weiming Wen , Yi Mang Yang, Jiaping Zhang, Mingyang Zhou, Kevin Jesse, Austin Chau, Antara Bhowmick, Shreenath Iyer, Giritheja Sreenivasulu, Runxiang Cheng, Ashwin Bhandare, Zhou Yu
- University of California
- Published at
- Alexa Prize 2018
- Key Points and My Comments
- XiaoIce와의 차이점
- Dialog state에 대한 정의가 명확하지 않음
- 따라서 state에 따른 policy와 action이 정의되는 느낌이 아님
- Gunrock은 NLU를 통해 넘어온 정보를 기반으로 Intent를 보고 주제별 서브 모듈에 던지는 느낌
- 즉, 유한한 주제에 대해 대화 스킬셋(모듈)을 갖춘 통합 시스템이라고 볼 수 있지 않나
- 이에 비해 XiaoIce는 NLU를 통해 넘어온 정보를 기반으로 적절한 토픽을 가미해서 다양한 어프로치로 말을 검색하고 만들어냄
- Gunrock은 특정 주제에 대해 깊게 말하는 게 목적이라 그런듯. XiaoIce는 정말 잡담까지 할 수 있는 것 같고
- XiaoIce와의 차이점
Abstract
- 토픽 전환이나 질의 응답과 같이 넓은 범위의 다양한 유저 behavior를 다룰 수 있는 context-aware hierarchical dialog manager를 개발함
- Robust한 3단계의 NLU 모듈을 디자인함
- 음성합성을 통해 사람다움을 향상시키고자 함
- Amazon Alexa Prize 2018 우승함
1. Introduction
- 45일의 평가 기간동안 하루 평균 500개의 대화(세션)을 얻음
- 전체 개발 기간동안 총 48만개의 대화 턴을 얻음
- 논문에서 제안하는 open-domain social bot인 Gunrock은 특정한 혹은 유명한 주제에 대해 깊이 대화를 나눌 수 있을 정도의 넓고 다양한 사회적 주제를 커버하는 능력을 통해 사람-사람 간의 자연스러운 대화를 모방하고자 함
- NLU: NER, Intent(Dialog Act), Sentiment, Coreference
2. Related Work
- Cornell Movie Dialogs, Reddit 등의 데이터 사용
3. Architecture
3.1 System Overview
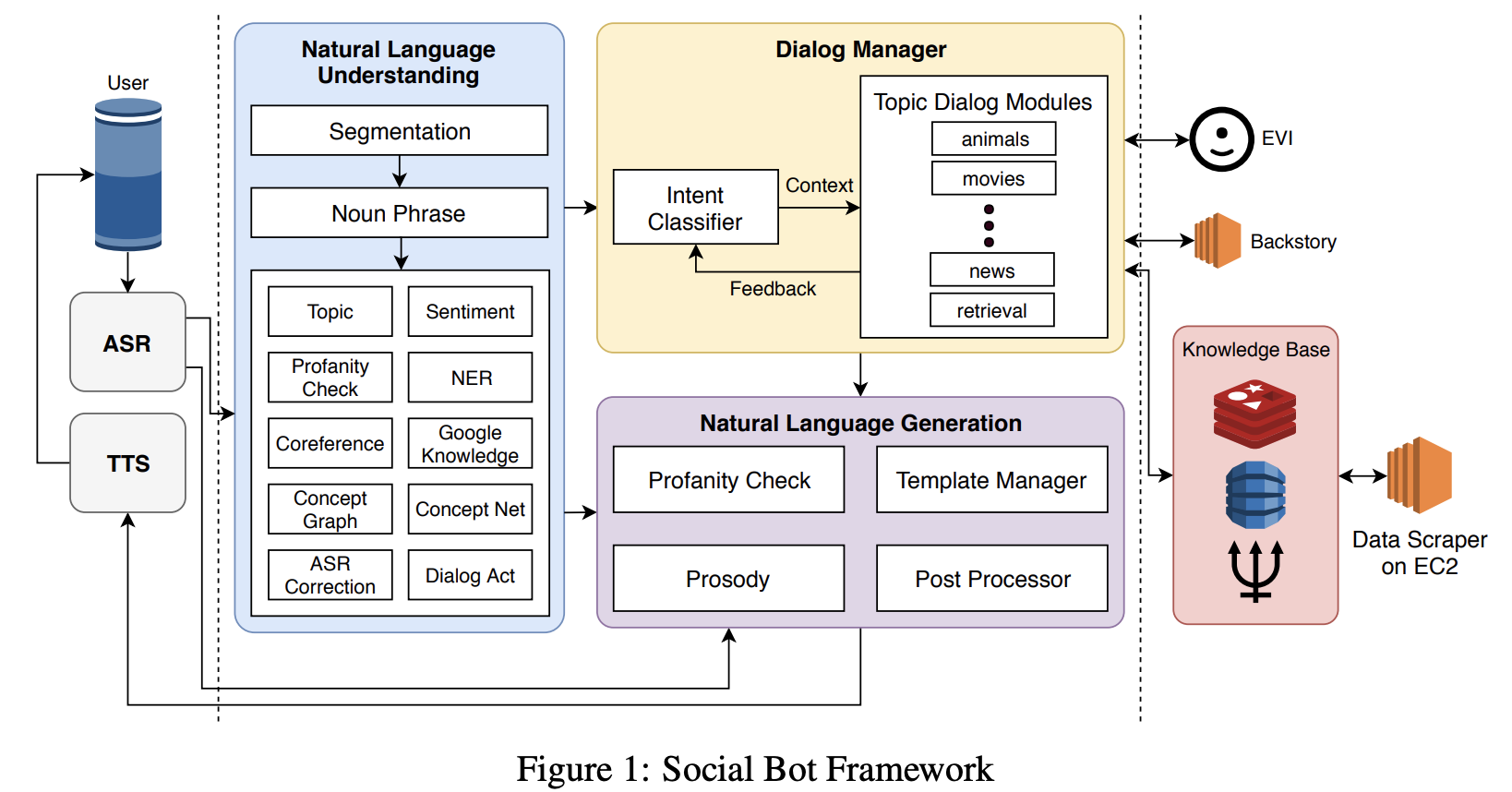
- NLU는 12개의 컴포넌트로 구성
- 크게는 1) multiple sentences에 대한 segmentation, 2) noun phrase 추출, 3) 그 결과를 여러 NLP 컴포넌트를 통해 분석, 으로 이루어짐
- DM은 Intent Classifier가 있는데, 의도를 분석해서 movies, sport, animal 등의 토픽 대화 모듈로 연결시키는 역할을 함
- NLG는 output에 대한 template을 관리함
3.2 Automatic Speech Recognition
- 음성 쪽은 패스
3.3 Natural Language Understanding
3.3.1 Sentence Segmentation
-
사람들이 길고 복잡하게 말하는 것도 처리해야 한다.
- Cornell Movie-Quotes Corpus의 30만개의 대화 중 약 2만개의 발화에 대해 breaking point를 직접 labeling
- Example
- “Alexa that is cool what do you think of the Avengers”
- “Alexa <BRK> that is cool <BRK> what do you think of the Avengers <BRK>”
- Model
- fastText word embedding
- Attention-Seq2Seq
- 2-layer Bi-LSTM Encoder
- 2-layer RNN Decoder
- 30 epochs 정도 학습시켰을 때, 96%의 Test 성능을 보임
3.3.2 Noun Phrase Extraction
- Stanford CoreNLP constituency parser 사용
- 쓸모없는 Stopword(e.g. it, all) 제거
- Future Work으로 dependency parser를 이용하는 방법을 고려중
3.3.3 Entity Recognition
- 기존의 NER 툴(Stanford CoreNLP, spaCy)은 대소문자에 매우 의존적임
- 또한, general한 entity를 잡아내기 쉽지 않음
- 따라서 기존 NER을 안쓰고 추출한 Noun Phrase에 대해 Knowledge Graph를 통해 entity를 잡아냄
- Google Knowledge Graph, Microsoft Concept Graph 등에 대해서 Noun Phrase를 검색하고 신뢰도가 높은 경우 이를 entity로 인식
- 예를 들어, “tomb raider”를 검색하면 “video game series”라는 label이 높은 신뢰도를 갖고 있고, 따라서 ”tomb raider”를 “video game series”라고 태깅
3.3.4 Coreference Resolution
- 일종의 대명사 처리 정도로 이해하면 됨
- 기존 모델들(CoreNLP, NeuralCoref)는 대화 데이터로 학습된 것이 아니기에 잘 작동하지 않음
- 그래서 새로 labeling을 해서 학습시킨듯함
3.3.5 ASR Correction
- 패스
3.3.6 Dialog Act Prediction
- Annotated 대화 데이터가 없기 때문에, Switchboard Dialog Act Corpus(SwDA)를 사용
- 2-layer Bi-LSTM, 2-layer CNN 등을 사용 (w/ fastText)
- 성능은 둘다 85% 정도로 비슷함
- 현재 ELMo와 Recurrent Convolutional NN으로 계속 실험을 진행 중이라고 함
3.3.7 Topic Expansion
- Knowledge Graph로서 ConceptNet을 이용
- 현재 얘기하는 토픽(entity)으로부터 확장시켜가며 대화를 이어갈 수 있도록 함
- 예를 들어, 현재 자동차에 대해 얘기하고 있다면 Knowledge Graph 상에서 확장(retrieve) 가능한 “Volvo”에 대한 얘기로 주제를 확장해볼 수 있음
- (NLU가 아니고 DM쪽에서 처리하는 게 맞지않나?)
3.4 Dialog Management
- 2-level Hierarchical Dialog Manager가 대화를 관리함
- High-level에서는 NLU의 output을 기반으로 적절한 topic dialog module을 선택함
- Low-level에서는 선택된 topic dialog module이 실행됨
3.4.1 High-Level System Dialog Management
- Intent Classifier
- Common Alexa Prize Chats(CAPC) dataset를 사용 (17년 대회 데이터로 만듬)
- System Request(“play music”, “turn on the lights”) 따로 처리
- 기본적인 Intent 파악과 함께, KG등을 기반으로 토픽(topic intent)을 잡아냄
- Dialog Module Selector
- Intent Classifier로부터 찾아낸 topic intent를 통해 dialog module을 선택
- 예를 들어, “let’s talk about movies”라는 발화가 들어오면 “movie”라는 걸 Intent Classifier가 포착하고 Selector는 movie module을 선택함
3.4.2 Low Level Dialog Management
- Topic Dialog Modules (11개)
- Animal: Reddit API을 이용해 응답을 찾아서 사용
- Movie and Book: TMDB API, Goodreads API, IMDB 등을 이용
- Music: Spotify’s million Playlist dataset에 있는 artist에 대해 얘기를 함
- Sport: 최신 정보가 중요. Reddit, Twitter, Moments, News 등 활용
- Game: IGDM
- Psychology and Philosophy: TED talk
- Holiday, Travel, Technology and Science, News, Retrieval
- 말을 만드는 것이 아니라, 해당 주제에서 흥미로운 정보를 “찾는 것”
- 정보를 추려서 NLG에 주면 템플릿 기반으로 발화 생성을 진행
3.5 Knowledge Base
- Fact 컨텐츠를 담당하는 KB랑 Opinion 컨텐츠를 담당하는 KB로 나눔
3.6 Natural Language Generation (NLG)
- 같은 말을 되풀이하지 않고, 다양성을 주기 위해 템플릿 기반으로 생성
4. An Example Dialog

- 유저가 관심을 가질 수 있게, 관심사를 고려하여 fact, experience, opinion 등 발화를 만듬
- acknowledgement 역시 사람답게 만드는데 중요한 역할을 한다고 생각
5. Results ans Analysis
- 대회 기간동안 성능이 계속 향상되었는데, 3단계의 NLU와 계측적 토픽 전이 관리 그리고 음성합성이 큰 영향을 주었다고 봄
5.1 Module Performance Analysis
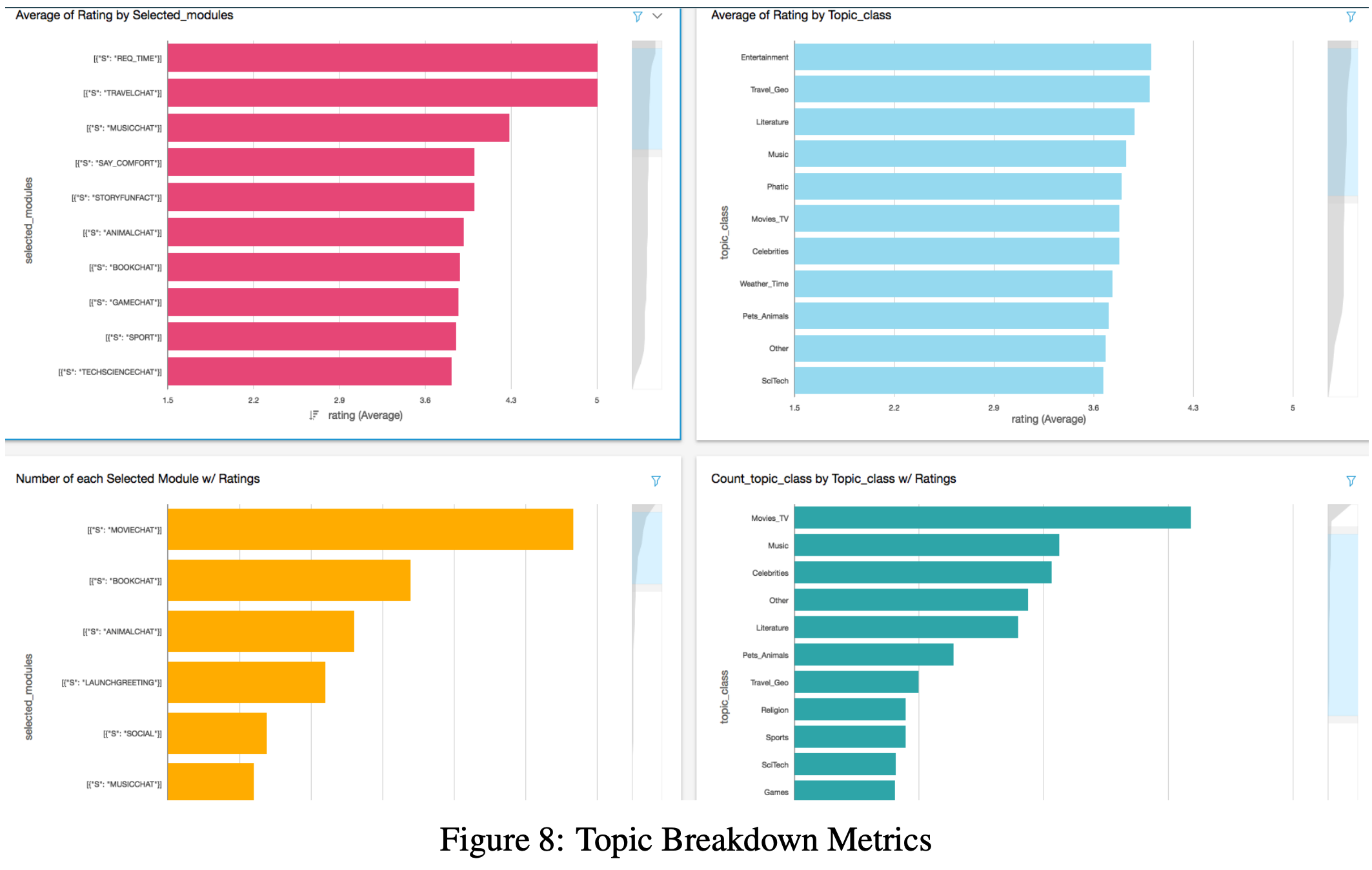
5.1.1 Topic level analysis
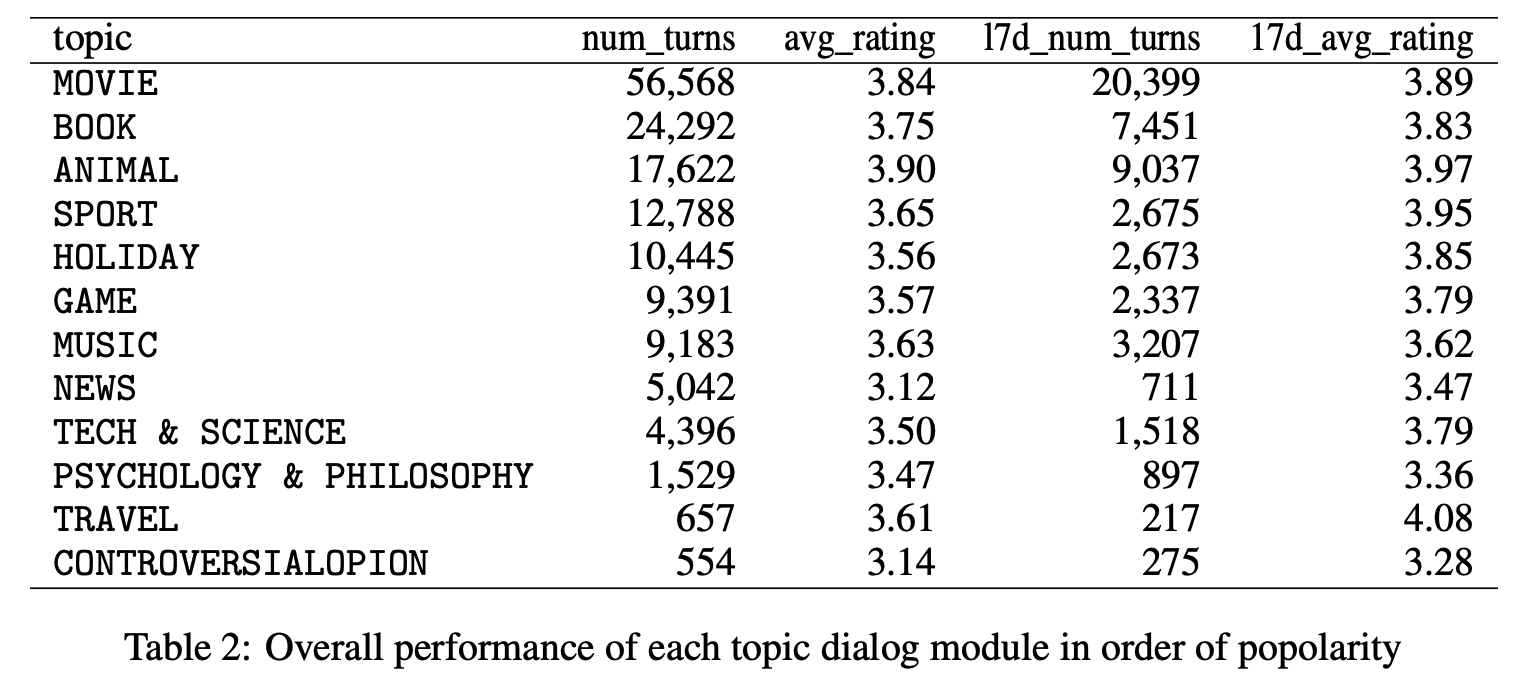
- Table 2는 토픽 대화 모듈(topic dialog module)에 따른 턴 수와 평균 점수를 보여줌
- 대회기간동안 MOVIE가 가장 널리 다뤄졌고, ANIMAL이 가장 점수가 좋았음
5.1.2 Lexical analysis
- 사람들이 얘기하고 싶어하는 엔티티(주제)에 대해서 unsupervised로 분석해봄
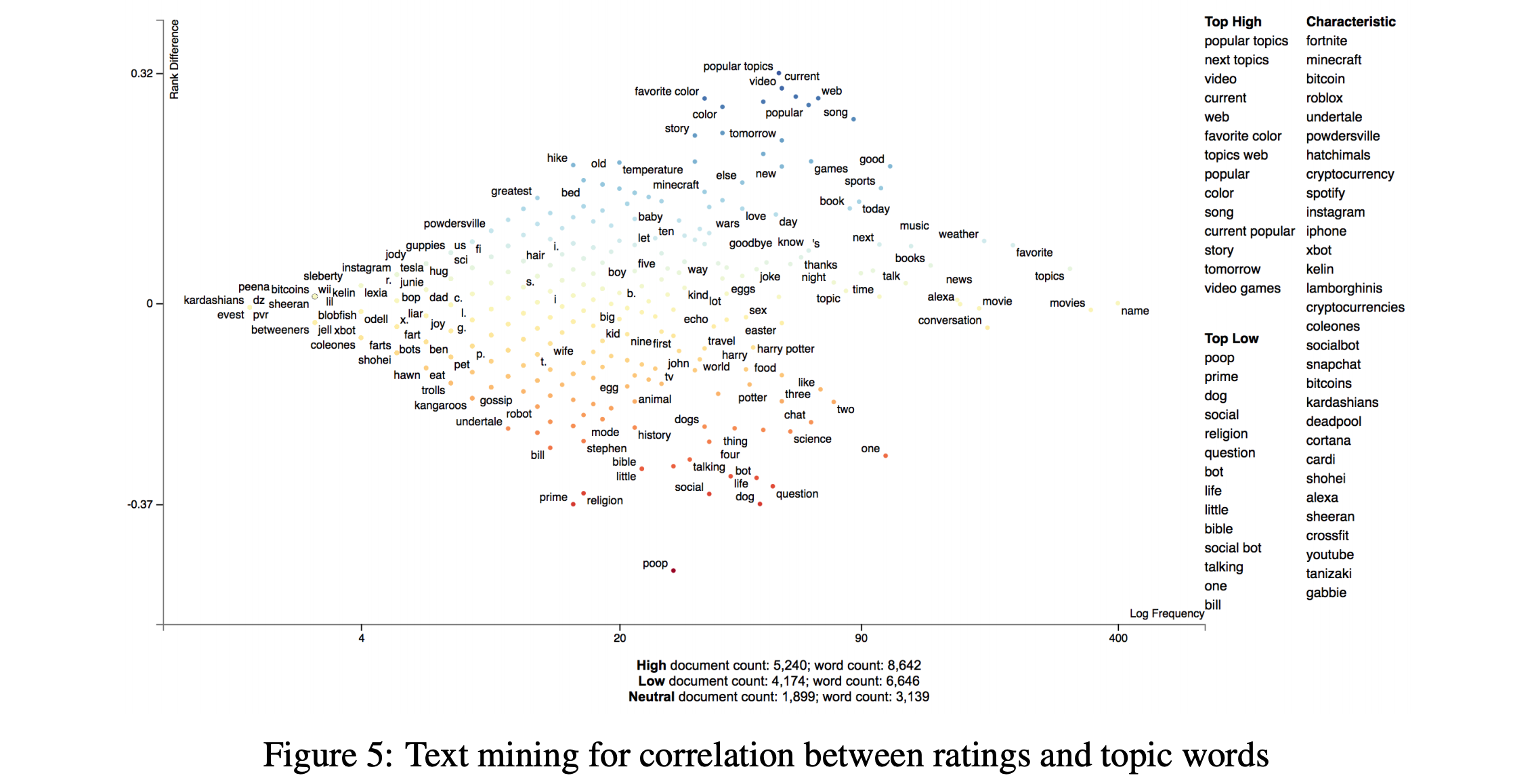
- Figure 5는 대화에서 나온 엔티티들과 대화의 점수 간의 correlation을 보기 위해 정성적 평가를 해본 것임
- x축은 해당 엔티티의 빈도수이고, y축은 단어와 점수을 나타내는 지표임
- 사람들은 기술, 게임, 동물에 대해서 많이 얘기하고 싶어하는데 반면 점수는 낮게 주는 경향이 있음. “robots”, “undertake”, “dog” 등의 단어들이 이런 걸 나타냄
- 그리고 논란이 될만한 주제와 낮은 점수가 상관성이 있다는 걸 발견함. “religion”, “gossip”, “poop” 등이 이에 해당함
- 그리고 사람들은 최근 이벤트에 대해서 얘기하고 싶어함
5.2 Dialog Strategy Effectiveness
5.2.1 Acknowledgement with Knowledge Graph reasoning
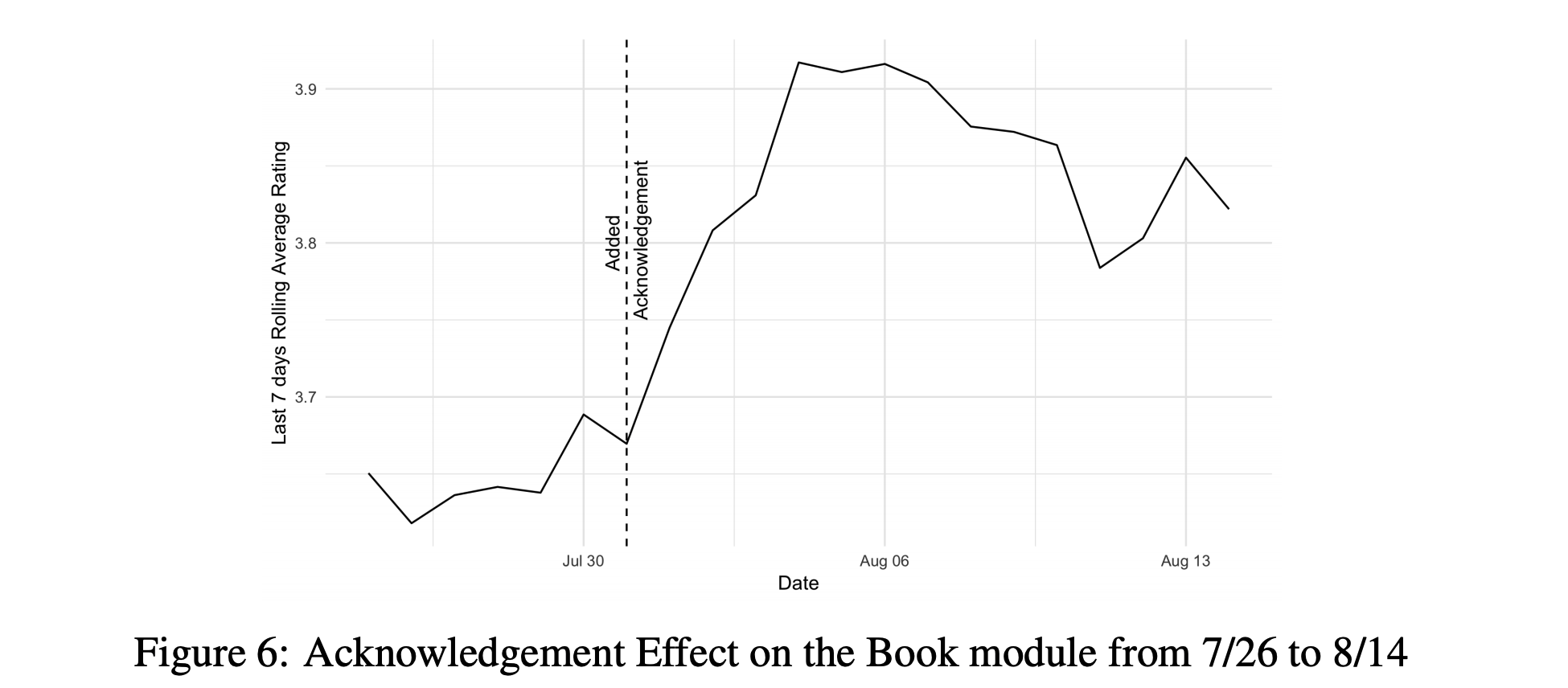
- Non-task oriented dialog system에서 grounding은 매우 효과적인 전략임
- Acknowledging(아는 척 하는 거)이 매우 중요함 (Figure 6 참조)
- 예를 들어, 책 모듈에서 사용자가 논픽션보다 픽션을 좋아한다고 하면 “오 나 해리포터 시리즈 읽어봤어” 라고 답하는 거임
- 이러려면 해리포터가 대표적인 픽션 책이라는 지식을 알고 있어야 함
- 따라서 knowledge graph를 적절히 활용하는 것이 필요
5.3 System Latency
- 패스
6. Visualization Tool
7. Conclusion
- Introduction과 같은 내용
8. Future Work
- 대회 때문에 엄밀히 실험하고 분석하지 못한 부분이 있음
- 대회 끝나고 A/B 테스트 같은 거 해보려고 함
- 그리고 몇몇 부분들은 더 향상시켜보고자함
- 각 유저 별로 유니크한 대화 경험을 주기 위해 유저의 성별, 성격, 관심사를 기반으로 토픽을 선택하는 성능을 향상시킬 거임
- 또한 upcoming 이벤트나 관심 컨텐츠를 추천하는 시스템을 만드는 것도 생각하고 있음
- 더 나은 dialog policy를 위해서 강화학습을 도입할까 싶음
- 또한 social citchat과 task-oriented를 합쳐볼 거임. 유저가 가끔 레스토랑 추천과 같이 특정 목적을 갖고 물어볼 때가 있기 때문에
- 그리고 data-driven opinion answering이나 토픽에 대한 debate를 할 수 있는 모델을 만들거임
- 마지막으로 자동으로 유저와의 대화를 학습할 수 있게 online learning 쪽도 알아보고 있음

Joohong Lee
Machine Learning Researcher