ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators (ICLR 2020)
- 12 mins- Paper Link: https://openreview.net/pdf?id=r1xMH1BtvB
- Author
- Kevin Clark, Minh-Thang Luong, Quoc V. Le, and Christopher D. Manning
- Stanford University & Google Brain
- Published at
- ICLR 2020
Abstract
- Masked language modeling은 대표적으로 BERT가 input을 $[MASK]$로 치환하고 이를 원본 token으로 재복원하는 방식의 pre-training method임
- Downstream task으로 transferring 했을 때 좋은 성능을 보이긴 하지만 많은 양의 계산 비용이 듬
- 이런 문제를 해결하기 위해서, replaced token detection 이라는 sample-efficient pre-training task를 제안함
- 이 기법은 input을 masking하는 것 대신에 small generator network로부터 sampling 된 그럴싸한 token으로 치환함
- 그 다음, 모델이 masked token의 원본을 예측하면서 학습하는 것 대신에 discriminative model을 둬서 각 token이 실제 token인지 generator가 만든 가짜 token인지 판별하는 학습을 시킴
- 이러한 Replaced token detection task는 input token 전체에 대해서 학습하기 때문에, 전체 token 중에 작은 부분만을 masking해서 학습하는 기존 MLM 보다 훨씬 효율적인 학습을 할 수 있으며, 이를 철저한 실험을 통해서 증명함
- 결과적으로 동일한 모델 크기, 데이터, 컴퓨팅 파워에 대해서 BERT를 outperform했음
- 이런 결과는 모델 크기가 작을 때 더욱 부각됨. 이 기법으로 single GPU 4일 학습한 모델이 GPT 보다 GLUE에서 좋은 성능을 얻음 (GPT의 학습량이 30배 많은데도 불구하고)
- 또한 RoBERTa와 XLNet의 1/4의 컴퓨팅으로 비슷한 성능을 뽑았고, 같은 양으로 학습을 시키면 outperform함
1. Introduction
- 현재 state-of-the-art representation learning method는 일종의 denoising autoencoder 학습이라고 볼 수 있음
- 주로 MLM이라는 원본 input에서 약 15% 정도의 token을 masking하고 이를 복원시키는 task를 통해 학습을 함
- 기존 (autoregressive) language modeling 학습에 비해 bidirectional 정보를 고려한다는 점에서 효과적인 학습을 할 수 있었음
- 하지만 이런 MLM 기반의 기법들은 문제가 있음
- 고작 15%만 밖에 학습을 못함
- (그래서) 학습하는데 비용이 많이 듬
- 학습 때는 $[MASK]$ token을 모델이 참고하여 예측하지만 실제(inference)로는 $[MASK]$ token이 들어오지 않음
- 이런 점들을 해결하기 위해 replaced token detection 이라는 새로운 pre-training task를 제안함
- Replaced token detection: 실제 input의 일부 token을 generator를 통해 그럴싸한 가짜 token으로 바꾸고 discriminator가 각 token이 원본에서 온 진짜인지 생성(sampling)해낸 가짜인지 맞추는 task
- 15%가 아닌 input 문장의 전체 token에 대해서 학습을 할 수 있어서 상당히 효율적이고 효과적임
-
얼핏 보면 GAN과 유사하지만 generator가 maximum likelihood로 학습한다는 점에서 adversarial은 아님
- 위와 같은 방식으로 학습시킨 pre-trained LM인 ELECTRA (for “Efficiently Learning an Encoder that Classifies Token Replacements Accurately”)를 제안함
- ELECTRA는 앞선 설명과 같이 모든 token에 대해서 학습을 할 수 있어서 BERT보다 훨씬 빠르게 학습이 가능하고 최종 학습을 완료하면 downstream tasks에서 더 좋은 성능을 보임
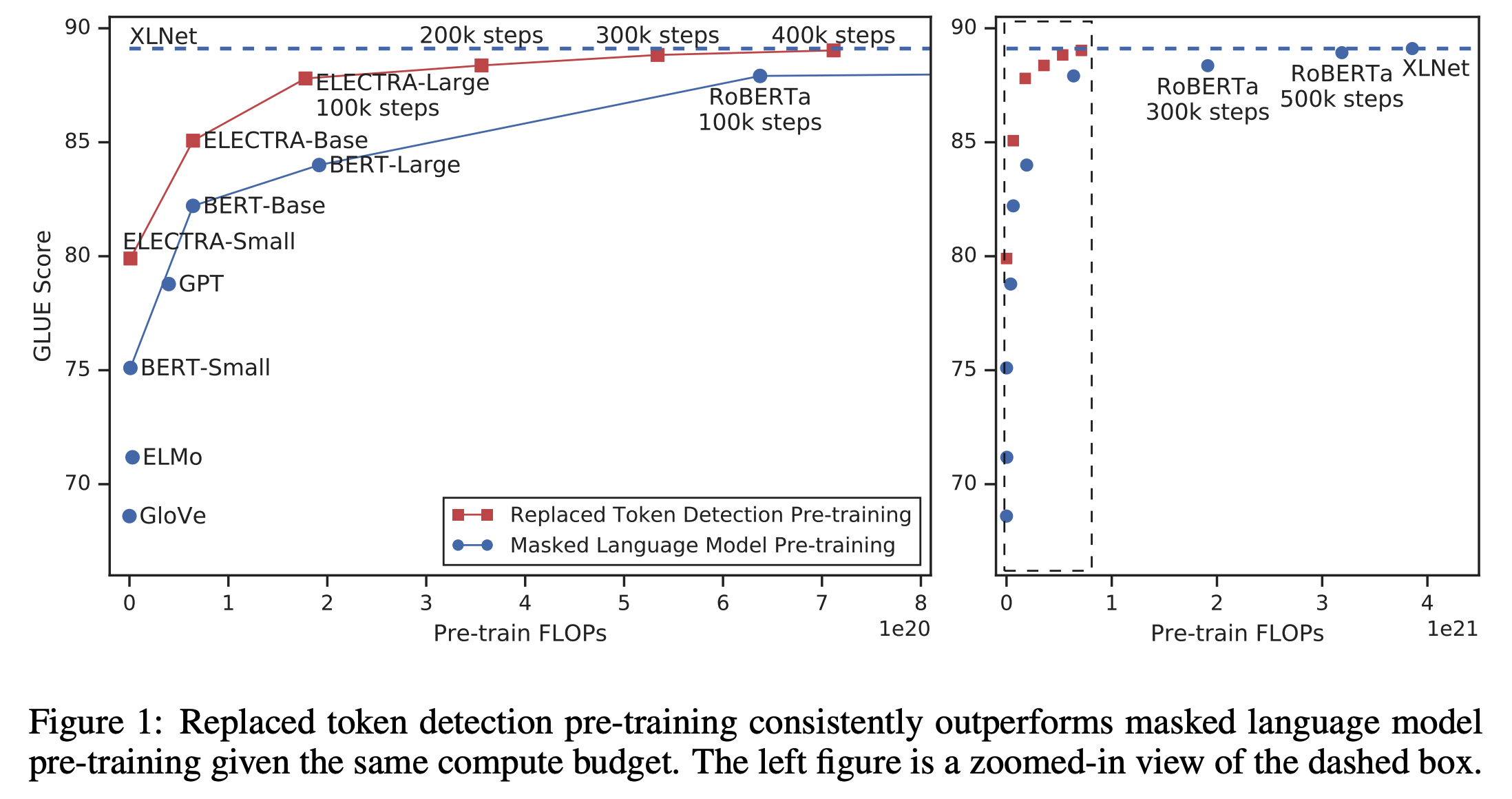
- Figure 1을 보면 ELECTRA가 다른 approaches에 비해서 매우 빠르게 성능이 향상되는 것을 볼 수 있음
- 같은 크기의 모델들에 비교하면 최종 성능 포함 모든 과정에서 더 높은 GLUE 성능을 보임
- ELECTRA-Small은 single GPU로 4일이면 학습이 가능 (이는 BERT-Large의 1/20 parameter, 1/135 계산량(compute)에 해당하는 수치)
- 그럼에도 불구하고 BERT-Small 보다 GLUE에서 5점이나 높고, 심지어는 GPT 보다도 높음
- Large scale에 대해서 역시 좋은 성능을 보임
- ELECTRA-Large는 RoBERTa나 XLNet 보다 더 적은 parameter, 1/4의 계산량으로 학습했지만 이들과 비슷한 성능을 보임
- GLUE에서 ALBERT (Lan et al., 2019) 보다도 outperform했고 SQuAD 2.0은 SOTA를 찍음
- 종합적으로 봤을 때, 제안한 discriminative task를 통해서 모델이 더 어려운 negative sample에 대해서 학습했고, 기존 language representation learning approaches보다 더 효과적이고 효율적인 학습을 함
2. Method
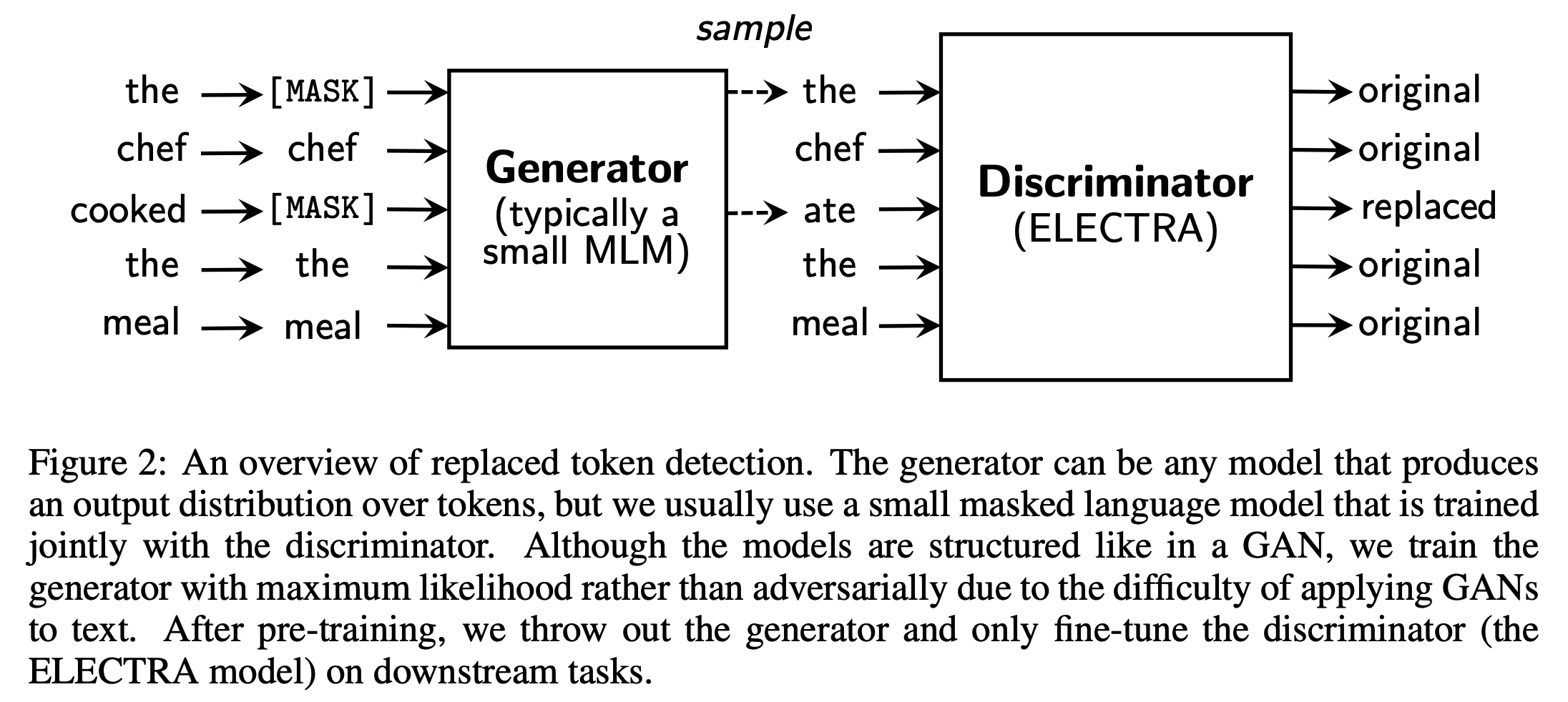
- Replaced token detection으로 학습하기 위해서 generator $G$와 discriminator $D$, 두 개의 network가 필요함
- 두 network는 Transformer Encoder 구조이며, sequence of input tokens $\textbf{x} = [x_1, x_2, …, x_n]$을 입력으로 받아서 sequence of contextualized vector representations $h(\textbf{x}) = [h_1, h_2, …, h_n]$로 매핑시킴
Generator
- Generator $G$는 BERT의 MLM과 동일하게 학습함
- Input $\textbf{x} = [x_1, x_2, …, x_n]$에 대해서 masking할 position set $\textbf{m} = [m_1, m_2, …, m_k]$을 결정함
- Position은 integers between 1 and $n$이며, 아래와 같이 수학적으로 표현할 수 있음
- $m_i \sim \text{unif} { 1, n } \; \text{for} \; i = 1 \; \text{to} \; k$
- Masking할 개수 $k$는 보통 $0.15n$을 사용 (전체 token의 15%)
- Position은 integers between 1 and $n$이며, 아래와 같이 수학적으로 표현할 수 있음
- 결정한 position에 해당하는 input token을 $[MASK]$로 치환함
- 이 과정을 $\textbf{x}^{masked} = \text{REPLACE}(\textbf{x}, \textbf{m}, [MASK])$와 같이 표현
- Masked input $\textbf{x}^{masked}$에 대해서 generator는 아래와 같이 원래 token이 무엇이었을지를 예측함
-
이런 과정을 수학적으로 표현하면 아래와 같음 ($t$ 번째 token에 대한 예측).
\[p_G (x_t | \textbf{x}^{masked}) = \exp(e(x_t)^T h_G(\textbf{x}^{masked})_t) / \sum_{x'} \exp(e(x')^T h_G(\textbf{x}^{masked})_t)\] -
또한 $e(\cdot)$는 embedding을 의미함. 즉, 위의 식은 LM의 output layer를 embedding layer와 tying(weight sharing)하겠다는 의미
-
- 최종적으로 아래와 같은 MLM loss를 통해 학습
- Input $\textbf{x} = [x_1, x_2, …, x_n]$에 대해서 masking할 position set $\textbf{m} = [m_1, m_2, …, m_k]$을 결정함
Discriminator
- Discriminator $D$는 input tokens에 대해서 각 token이 original인지 replaced인지 binary classification으로 학습함
- Generator를 이용해서 masked input token에 대한 예측을 진행함 (위의 generator의 1~3단계)
-
Generator에서 masking할 position set $\textbf{m}$에 해당하는 위치의 token을 $[MASK]$가 아닌 generator의 output distribution $p_G(x_t \textbf{x})$에 대해 sampling한 token으로 치환함. 이를 corrupt시킨다고 함 - Original Input: [“the”, “chef”, “cooked”, “the”, “meal”]
- Input for generator: [”$[MASK]$”, “chef”, “$[MASK]$”, “the”, “meal”]
- Input for discriminator: [“the”, “chef”, “ate”, “the”, “meal”]
- 첫번째 단어는 generator가 올바르게 “the”라고 예측함
- 세번째 단어는 generator가 원래 “cooked”인데 “ate”라고 잘못 예측함
-
이 치환 과정은 수학적으로 다음과 같음
\[\textbf{x}^{corrupt} = \text{REPLACE}(\textbf{x}, \textbf{m}, \hat{\textbf{x}}) \\ \hat{\textbf{x}} \sim p_G (x_i | \textbf{x}^{masked}) \; \text{for} \; i \in \textbf{m}\]
- Corrupted input $\textbf{x}^{corrupt}$에 대해서 discriminator는 아래와 같이 각 token이 original input과 동일한지 변형(corrupt)이 된 것인지 예측(binary classification)함
- Target classes (2)
- original: 이 위치에 해당하는 token은 원본 문장의 token과 같은 것
- replaced: 이 위치에 해당하는 token은 Generator에 의해서 변형된 것
-
이런 과정을 수학적으로 표현하면 아래와 같음 ($t$ 번째 token에 대한 예측).
\[D(\textbf{x}^{corrupt}, t) = \text{sigmoid}(w^T h_D(\textbf{x}^{corrupt})_t)\]
- Target classes (2)
- 최종적으로 아래와 같은 loss를 통해 학습
GAN과의 차이점
- 위의 training objective가 GAN과 유사하지만 몇 가지 다른 점이 있음
- Generator가 origianl token과 동일한 token을 생성했다면 이는 discriminator에서 positive sample로 처리 (GAN에서는 그래도 fake로 처리함)
- Generator가 discriminator를 속이기 위해 adversarial하게 학습하는 게 아니고 그냥 maximum likelihood로 학습함. 성능도 maximum likelihood가 더 좋음
- 일단 generator로부터 sampling하는 과정 때문에 adversarial하게 generator를 학습하는 게 어려움 (back-propagation 불가능)
- 그래서 reinforcement learning으로 이를 구현해보았지만 maximum likelihood로 학습시키는 것보다 성능이 별로였음 (see Appendix F)
- Generator의 input으로 noise vector를 넣어주지 않음
-
최종적으로는 large corpus $\mathcal{X}$에 대해서 위의 generator와 discriminator의 loss를 합쳐서 학습함
\[\min_{\theta_G, \theta_D} \sum_{\textbf{x} \in \mathcal{X}} \mathcal{L}_{\text{MLM}}(\textbf{x}, \theta_G) + \lambda \mathcal{L}_{Disc} (\textbf{x}, \theta_{D})\]- $\lambda$는 50을 썼다고 Appendix A에 나와있음. Discriminator는 binary classification이고 generator는 30000-way classification이여서 전반적으로 discriminator의 loss가 generator에 비해 매우 작음
- 앞에서 설명했듯이 sampling 과정이 있기 때문에 discriminator의 loss는 generator에게 back-propagate 되지 않음
- 위의 구조로 pre-training을 마친 뒤, generator는 버리고 discriminator만 취해서 downstream task에 대한 fine-tuning을 진행함
Experiments
3.1. Experimental Setup
- GLUE, SQuAD로 실험
- 데이터(Wikipedia, BooksCorpus), 모델 크기, hyperparameter 등 대부분의 실험 세팅을 BERT와 동일하게 가져감
- Large 모델의 경우 XLNet과 동일하게 맞춤
- English에 대해서만 했고, multilingual data는 future work
- 성능은 median of 10 fine-tuning runs from same pre-trained checkpoint로 측정
- Appendix에 futher training details and hyperparameter values가 있음
3.2. Model Extensions
Weight sharing
- Pre-training의 효율을 향상시키기 위해서 generator와 discriminator의 wieght를 sharing하도록 해봄
- Generator와 discriminator가 동일한 크기의 Tranformer라면 모든 weight를 tying할 수 있음
- 하지만 동일한 크기의 모델을 tying해서 쓰는 것보다 small generator를 쓰는 게 더 효율적이라는 사실을 알게 됨
- 이 경우에는 token and positional embedding만 sharing하도록 함
- Embedding size는 discriminator의 hidden size로 잡았고 generator의 경우 linear layer를 둬서 generator의 hidden size에 맞게 projection시킴
- Generator의 input과 output token embedding은 BERT와 마찬가지로 항상 tying 처리
- GLUE scores
- No tying: 83.5
- Tying token embeddings: 84.3
- Tying all weight: 84.4
- Discriminator는 input으로 들어온 token만 학습하게 됨. 하지만 generator는 output layer에서 softmax를 통해 vocab에 있는 모든 token에 대해 densly 학습을 함
- 그래서 embedding을 sharing하는 게 도움이 많이 되지 않았을까 싶음
- 반면, 모든 weight를 sharing하는 것은 약간의 성능 향상이 있지만 generator와 discriminator를 같은 크기로 맞춰야 한다는 큰 단점이 있음
- 그래서 이후 실험에서는 embedding만 sharing하도록 세팅함
Smaller Generators
- Generator와 discriminator의 크기가 같다면 ELECTRA를 학습하기 위해서 일반 MLM 모델에 비해 거의 두배 계산량이 커짐
- 이 문제를 해결하기 위해서 generator의 크기를 줄여봄. 구체적으로는 다른 hyperparameter는 그대로 두고 layer의 크기만 줄임
- 여기서 layer의 크기란, hidden size, FFN size, # of attention heads를 의미
- 거기에 추가로 학습 corpus에 등장하는 unigram의 distribution(frequency) 기반으로 sampling하는 매우 매우 간단한 unigram generator로도 실험을 해보았음
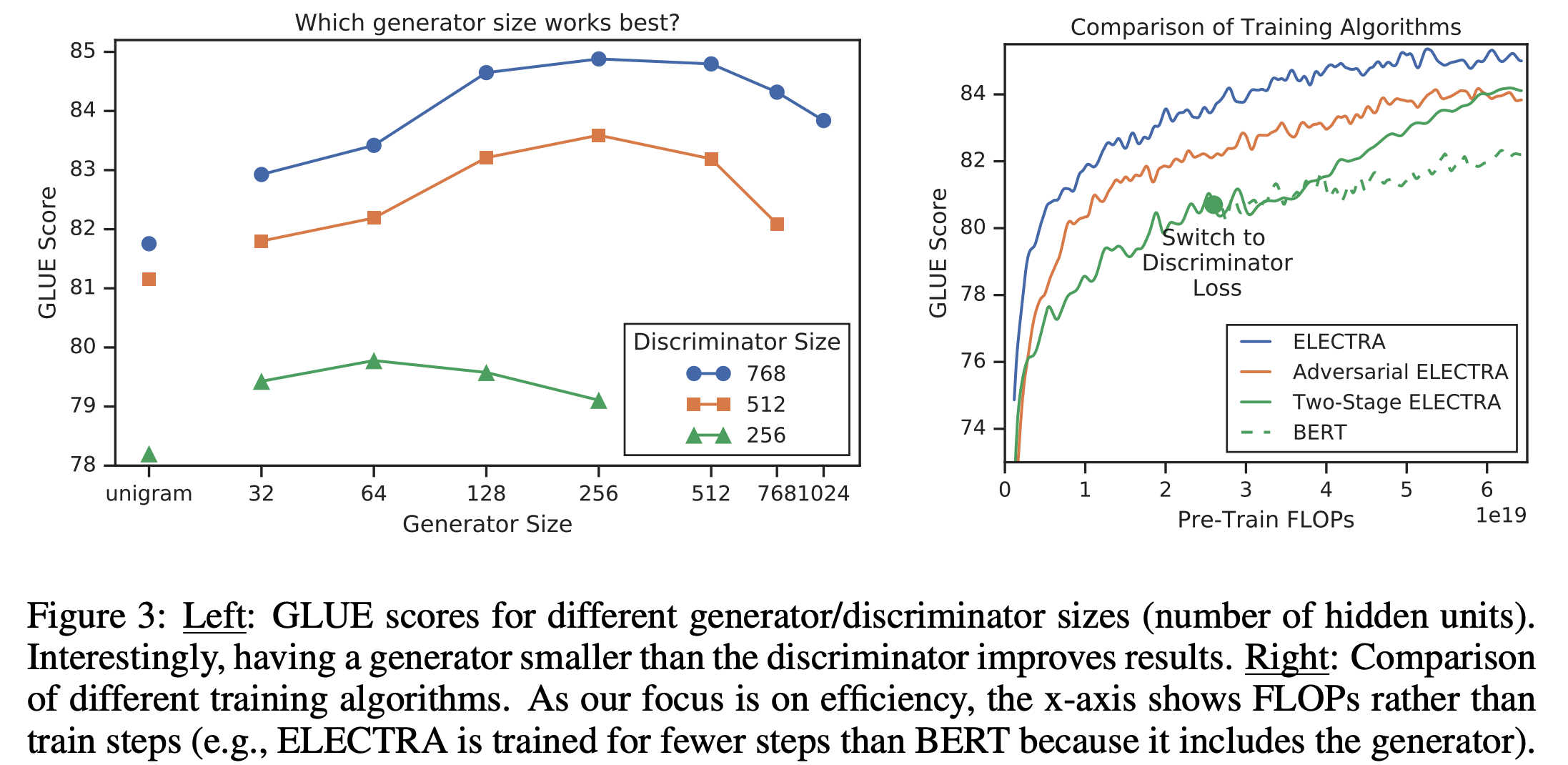
- 실험의 결과는 위의 Figure 3의 왼쪽과 같았으며 모두 동일하게 500K steps 학습시켰음
- 모두 500K steps만큼 학습했기에 작은 모델 입장에서는 계산량 대비 손해를 본 셈. 똑같은 계산량, 시간만큼 학습했다고 하면 작은 모델은 더 많은 step을 돌 수 있기 때문에
- (그럼에도 불구하고) 1/4에서 1/2 크기의 generator를 썼을 때 가장 성능이 좋았음
- 왜 이런 결과가 발생했을까?
- 아마 generator가 너무 강력하면 discriminator의 task가 너무 어려워져서 이런 현상이 발생하는 게 아닐까 추측함
- 게다가 discriminator의 parameter를 실제 데이터 분포가 아닌 generator를 모델링하는데 사용하게 될 수도 있음. (Generator가 강력하면 output 분포가 치우쳐져 있을 가능성이 높고 sampling의 결과가 다양하지 않아질 수 있어서 generator에 피팅된다는 말이 아닐까 싶음)
Training Algorithms
- 기본적으로 앞서 소개한 training objective로 generator와 discriminator를 jointly 학습함
- 이 방법과 다르게 아래와 같은 방법(two-stage)으로도 학습을 시켜봄
- Generator만 $\mathcal{L}_{\text{MLM}}$으로 $n$ steps 학습시킴
- Discriminator를 generator의 trained weight로 initialize하고 $\mathcal{L}_{\text{Disc}}$로 generator는 freeze하고 discriminator만 $n$ steps 학습시킴
- 또한 GAN처럼 adversarial training도 해봄 (Appendix F에 자세히 나옴)
- 결과는 Figure 3의 오른쪽과 같으며 그냥 joint training이 가장 좋았음
- 위의 two-stage 방법에서 discriminative objective로 바꾸니까 성능이 쭉 올랐다는 것을 볼 수 있음
- Adversarial training이 maximum likelihood training보다 underperform 한다는 것도 알 수 있었음. 이런 현상에 대한 원인은 다음과 같음
- Masked language modeling 성능이 안좋아서
- MLM 성능은 58% 밖에 안됨. Maximum likelihood로 학습한 generator는 65%
- 학습된 generator가 만드는 distribution의 entropy가 낮아서
- Output distribution은 하나의 token에 확률이 쏠려있고, 이러면 sampling할 때 다양성이 많이 떨어짐
- Masked language modeling 성능이 안좋아서
- Text를 위한 GAN의 이전 연구에서 위 문제가 발견된 바 있음 (Caccia et al., 2018)
3.3. Small Models
- 이 연구의 목적은 pre-training의 효율성 향상에 있음. 그래서 single GPU로도 빠르게 학습할 수 있는 수준으로 작은 모델을 만들어봄
-
ELECTRA-Small 모델의 hyperparameters는 아래의 Table 6과 같으며, 매우 작다는 걸 알 수 있음
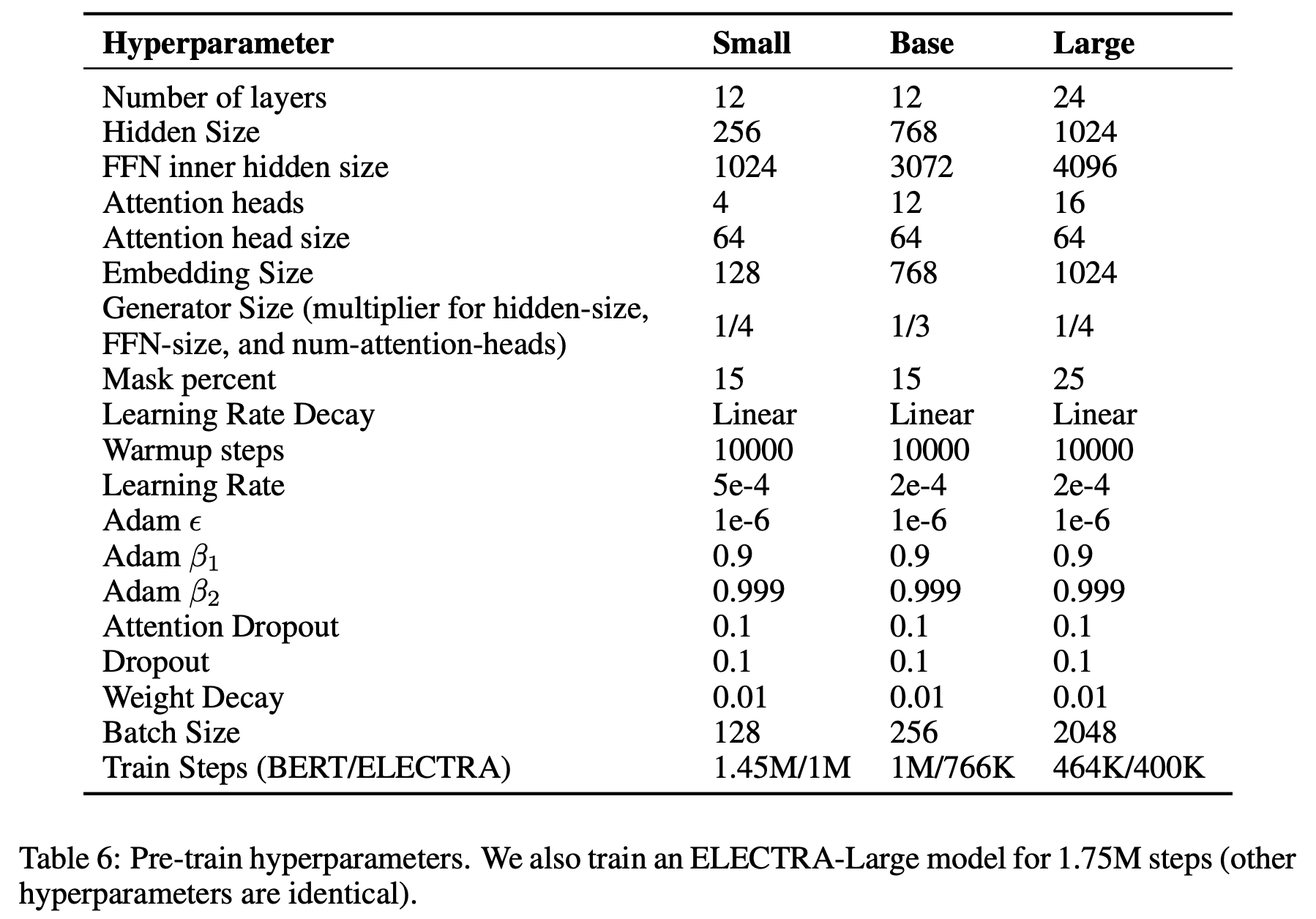
- 또한 공정한 비교를 위해 training FLOPs를 맞춰서 BERT-Small은 1.5M step, ELECTRA-Small은 1M step 학습을 시킴

- 결과는 위의 Table 1과 같이 ELECTRA-Small이 BERT-Small보다 좋은 성능을 보였고, 심지어는 훨씬 큰 모델인 GPT 보다도 좋은 성능을 보임
- 또한 매우 빠른 수렴 속도를 보임. Single GPU로 6시간 만에 꽤 쓸만한 성능을 보임
- ELECTRA-Base 역시 BERT-Base를 능가했을 뿐 아니라 심지어 BERT-Large 보다도 더 좋은 성능을 보임
3.4. Large Models
- Large 모델에 대해서도 실험을 해보았음. ELECTRA-Large의 크기는 역시 BERT-Large의 크기에 맞춰서 실험하였고 XLNet에서 사용한 데이터를 사용함
- 결과는 아래의 Table 2(dev), Table 3(test)와 같았음. 모델명 옆에 숫자는 학습 step을 의미함
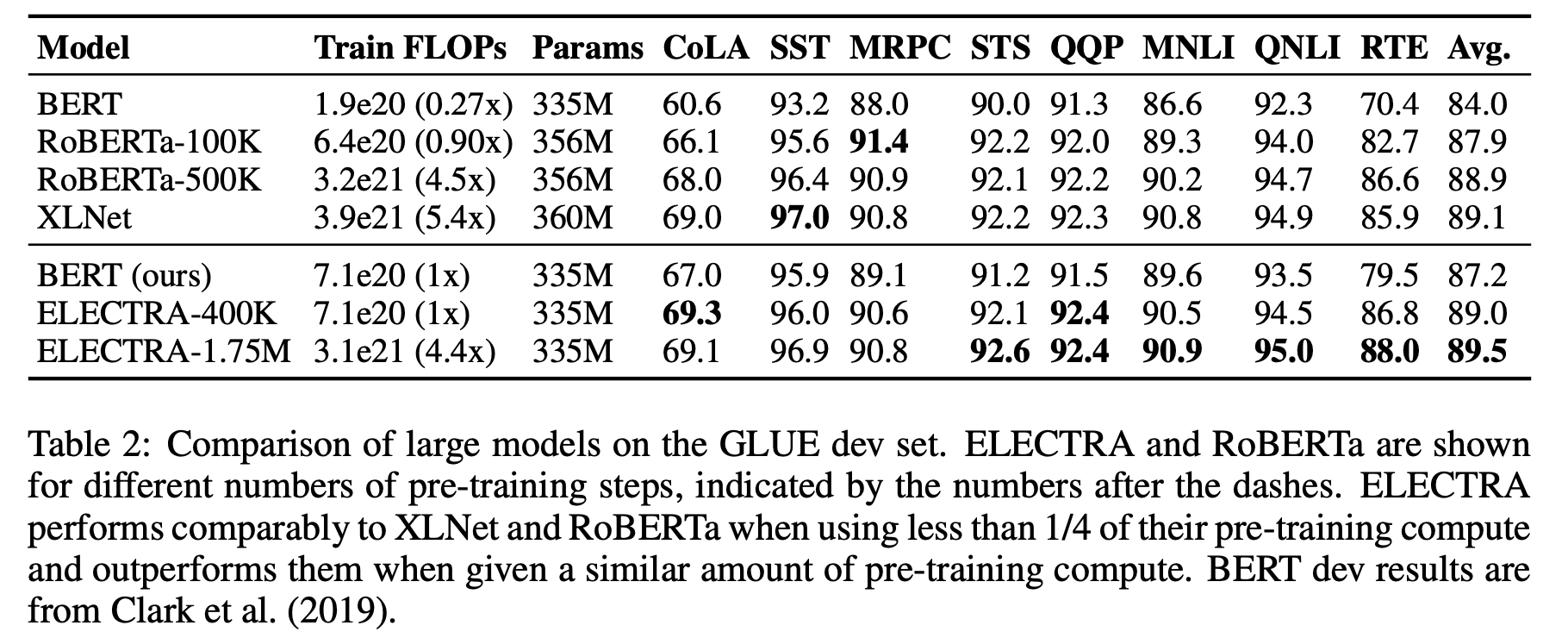
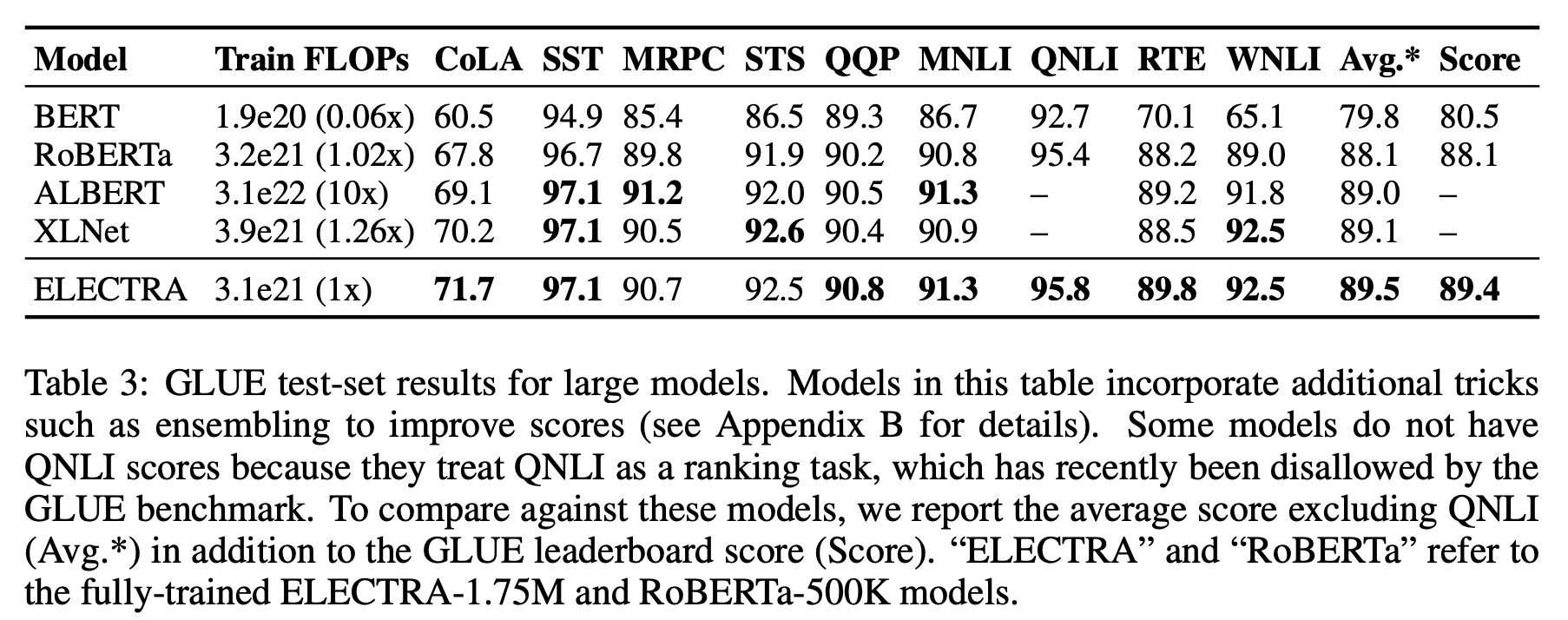
- ELECTRA-400K는 RoBERTa(-500K)나 XLNet에 비해서 1/4의 계산량(FLOPs)으로 comparable한 성능을 보임
- 더 많이 학습시킨 ELECTRA-1.75M은 이들을 뛰어넘는 성능을 보였고, 이 역시도 계산량은 두 모델보다 작음
- SQuAD에서도 마찬가지로 가장 좋은 성능을 보임 (논문의 Table 4 참고)
3.5. Efficiency Analysis
- ELECTRA가 왜 잘되는지 좀 더 자세히 이해해보기 위해 다음의 실험을 세팅함 (일종의 ablation study 느낌)
- ELECTRA 15%: ELECTRA의 구조를 유지하되, discriminator loss를 input tokens의 15%만으로 만들도록 세팅
- 목적: 학습 효율(15% vs 100%)로 인해 성능 차이가 생겼다는 것을 보이기 위해서
- Replace MLM: Discriminator를 MLM 학습을 하되, $[MASK]$로 치환하는 게 아니고 generator가 만든 token으로 치환
- 목적: Pre-training 할 때만 쓰고 fine-tuning 때는 없는 $[MASK]$ token에 대한 문제로 인한 성능 차이를 보이기 위해서
- All-Tokens MLM: Replace MLM처럼 하되, 일부(15%) token만 치환하는 게 아니고 모든 token을 generator가 생성한 token으로 치환
- BERT와 ELECTRA를 합친 버전
- 이 모델의 성능을 좀 더 계선하기 위해 sigmoid layer를 통해 input token을 카피할지에 대한 확률 $D$을 뽑는 copy mechanism을 도입
- 결과적으로 모델의 output distribution은 $D * \text{input-token-distribution} + (1-D) * \text{MLM-output-distribution}$와 같은 형태임
- ELECTRA 15%: ELECTRA의 구조를 유지하되, discriminator loss를 input tokens의 15%만으로 만들도록 세팅

- 결과는 위의 Table 5와 같으며, ELECTRA 15%와 Replace MLM 보다 훨씬 좋은 성능을 보였고 All-Tokens MLM은 그나마 ELECTRA에 가까운 성능을 보이며 BERT와 ELELCTRA의 성능 차이를 많이 줄였음
- 전반적으로 결과를 봤을 때, ELECTRA가 학습 효율도 굉장히 좋고 $[MASK]$ token에 대한 pre-train fine-tune mismatch 문제도 상당히 완화시켰다는 것을 알 수 있었음
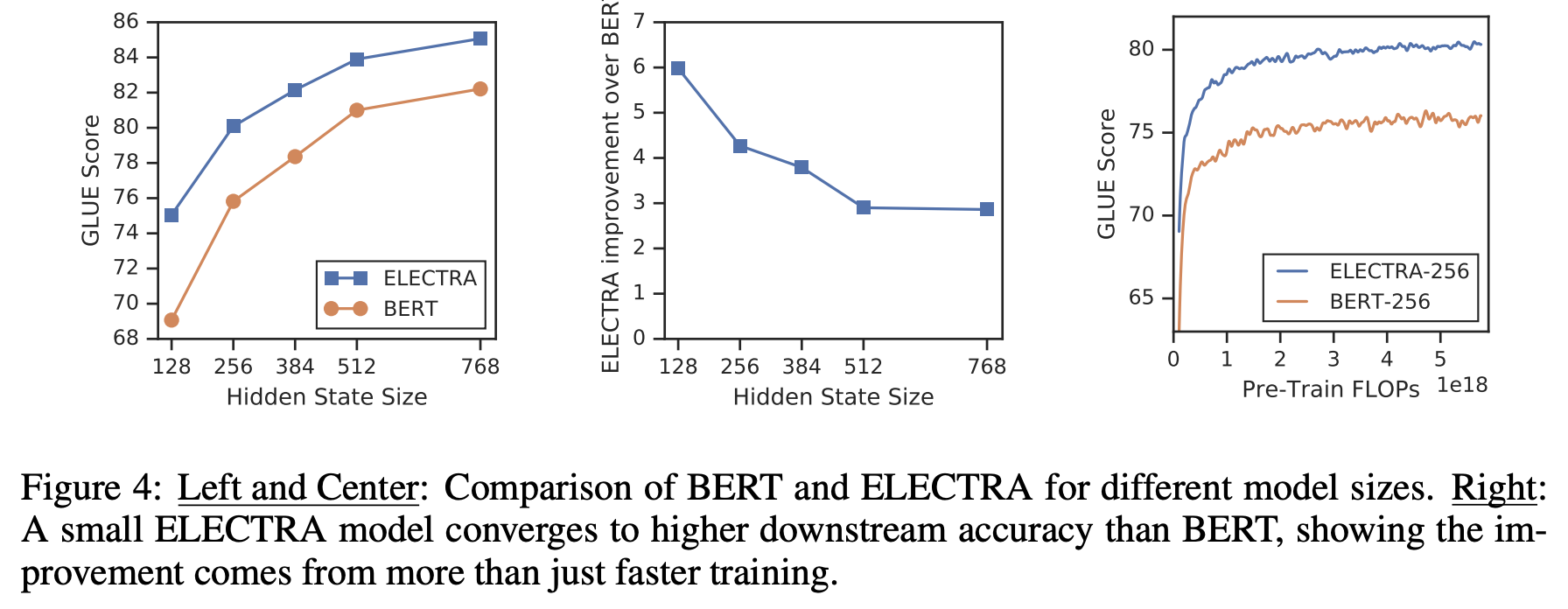
- Figure 4를 통해 Hidden size가 작아질수록 BERT와 ELECTRA의 성능 차이는 커진다는 사실을 알 수 있으며(see left and center), ELECTRA는 모델이 작아도 굉장히 빠르게 수렴한다는 것을 알 수 있음(see right)
- 결론적으로 ELECTRA가 BERT보다 parameter-efficient 하다고 볼 수 있음
4. Related work
- pass
5. Conclusion
- Language representation learning을 위한 새로운 self-supervised task인 replaced token detection을 제안함
- 이 방법의 key idea는 small generator network가 만들어 낸 high-quality negative sample와 input token을 구별하도록 text encoder를 학습시키는데 있음
- Masked language modeling에 비해, 제안하는 pre-training objective는 훨씬 compute-efficient하고 downstream tasks에 대한 결과 역시 더 좋음
- 상대적으로 적은 compute를 사용할 때 더 효과적이며, 이 연구를 통해서 연구자들이 적은 computing resource로도 pre-trained text encoder에 대한 많은 연구/개발을 할 수 있게 되길 바람
- Pre-training에 대한 future work들이 absolute performance만큼 compute usage와 parameter counts등의 efficiency를 고려했으면 하는 바람이 있음

Joohong Lee
Machine Learning Researcher