DiPair: Fast and Accurate Distillation for Trillion-Scale Text Matching and Pair Modeling (EMNLP 2020)
- 3 mins- Paper Link: https://arxiv.org/abs/2010.03099
- Author
- Jiecao Chen, Liu Yang, Karthik Raman, Michael Bendersky, Jung-Jung Yeh, Yun Zhou, Marc Najork, Danyang Cai, Ehsan Emadzadeh
- Google Research
- Published at
- EMNLP 2020
Abstract
- BERT 같은 pre-trained models이 많은 NLP/IR 태스크에서 높은 성능을 보여주고 있지만, 지나친 computational cost로 인해 실제 서비스에 deploy 되기는 어려움
- Knowledge Distillation (Hinton et al., 2015)을 통해서 가벼운 모델을 만들 수는 있지만, 현재 pairs (or tuples) of text를 위한 연구는 제대로 없음
- Text pair 태스크를 위한 새로운 Distillation Framework인 DiPair를 제안함
- DiPair는 scalable하며 quality와 speed를 모두 개선했음
- Academic과 real-world의 e-commerce benchmark를 통해서 성능을 평가했고, Cross-attention BERT 모델에 비해 350배 이상의 속도 향상이 있었음
Motivation
- 현실의 text matching task는 trillion+ text pairs에 대해서 점수를 계산해야 하고 기존의 BERT와 같은 Cross-encoder 구조의 모델은 이를 계산하는데 몇 년이 걸릴 수도 있음
- Solution 1:
- 이런 문제를 해결하기 위한 대표적인 방법으로 Knowledge Distillation 기법이 있음. 모델의 성능을 최대한 유지하면서 가볍게 만들어서 inference speed를 높이는 것
- 하지만 여전히 가벼운만큼 성능이 많이 떨어지는 quality-speed trade-off가 있음 (BERT-Tiny; Turc et al., 2019)
- Solution 2:
- 또다른 방법론으로는 pair of text를 독립적으로 모델링하는 Dual-encoder 구조를 사용하기도 함
- 이 경우 text의 embedding을 미리 계산하여 caching/indexing 할 수 있기 때문에 매우 빠른 inference가 가능함
- 하지만 아무래도 pair 사이의 interaction이 없어서 성능이 많이 떨어짐
- Proposed Method (DiPair): 둘의 장점을 취해서 Dual-encoder 구조에서 Cross-encoder로 Distillation해서 성능과 속도를 개선하자
Method: DiPair
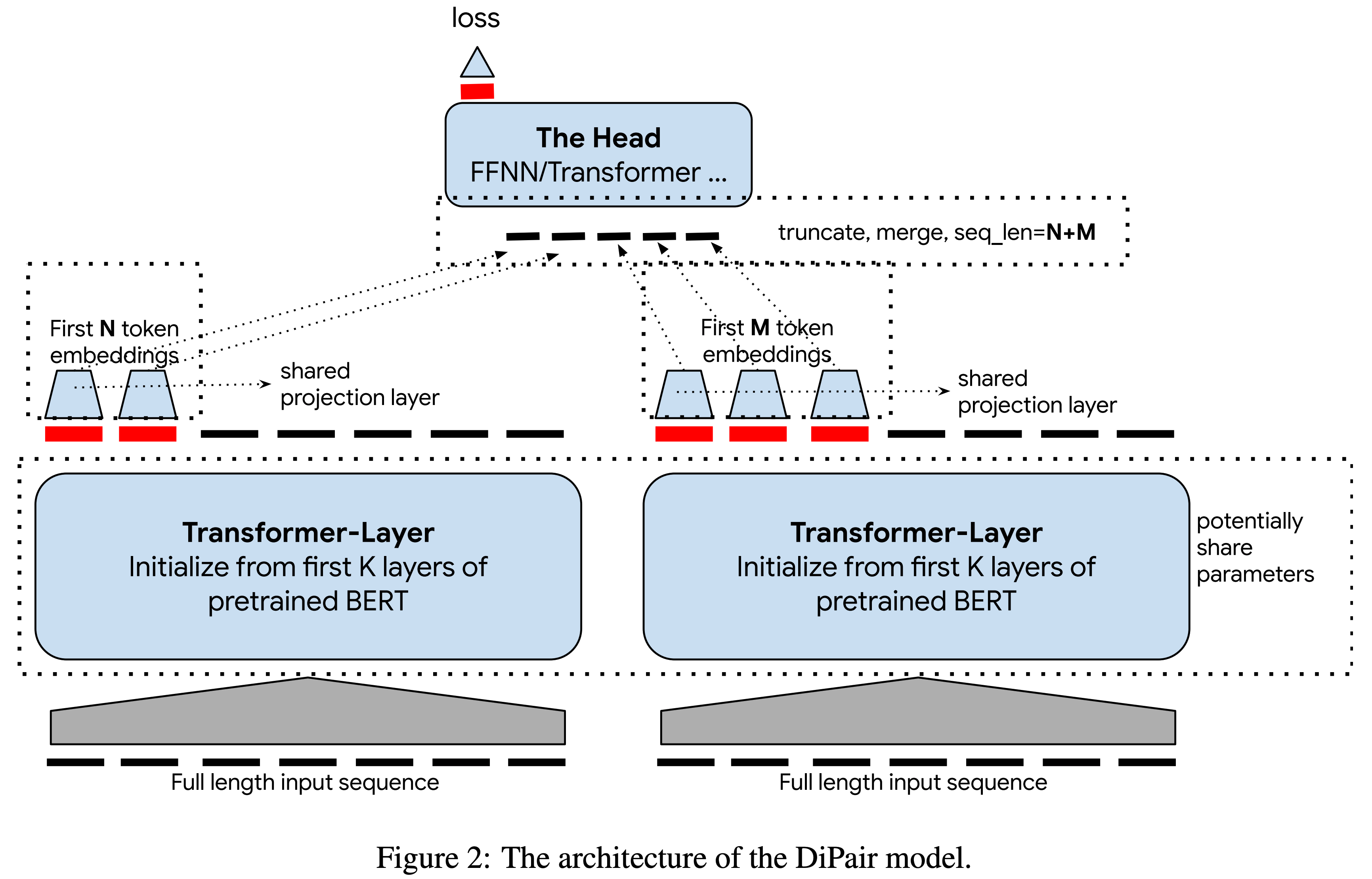
Dual-Encoder
- Initialize with pre-trained BERT
- Pair를 독립적으로 인코딩하므로서 Head에 따라 속도가 결정됨. 따라서 encoder의 capacity를 키워도 inference time이 증가하지 않음
Truncated Output Sequences
- Transformer 계열의 모델을 input sequence 길이에 따라 quadratic하게 속도가 느려짐
- 그렇다고 input을 truncate하면 성능이 급격하게 떨어짐 (see Figure 4 in the paper)
- Dual-encoder + Head 구조를 고안함
- Dual-encoder의 output들을 truncate and merge(concatenate)해서 얻은 truncated output sequence를 Head의 input으로 사용
- 병목은 결국 Head인데 input의 길이를 짧게 줄였기에 빠른 inference가 가능함
Projection Layer
- Encoder의 output을 더 작은 차원으로 projection 시키는 layer를 추가함
- 이러면 1) caching할 메모리를 줄일 수 있고, 2) Head의 속도를 향상시킬 수 있음
Transformer-Based Head
- BERT
- Add position embedding and segment embedding
- First token embedding (i.e., CLS embedding)을 최종 input pair의 representation으로 사용
- FFNN
- Feedforward neural network (FFNN)은 transformer-head보다 빠르면서도 꽤 괜찮은 성능을 보임
A Two-Stage Training Approach
- DiPair의 구조는 pre-trained 모델 위에 random initialized layer가 추가된 것이기 때문에, 모델 전체를 한번에 학습시키면 최대의 성능이 나오지 않음
- 학습 초기 단계에서 random initialied weight로 인해 이상한 예측 및 gradient가 발생하고 이로 인해 기존의 pre-trained weight에 내제된 knowledge가 파괴될 수 있음
- 이런 문제를 해결하기 위해 two-stage training strategy를 제안함 (similar with Wang et al., 2019)
- 처음에는 dual-encoder 부분을 freeze하고 새롭게 추가된 parameters (Head, Projection 등)만 학습을 시킴
- 어느정도 수렴된 후에 dual-encoder를 unfreeze해서 전체 모델을 학습시킴
Main Results
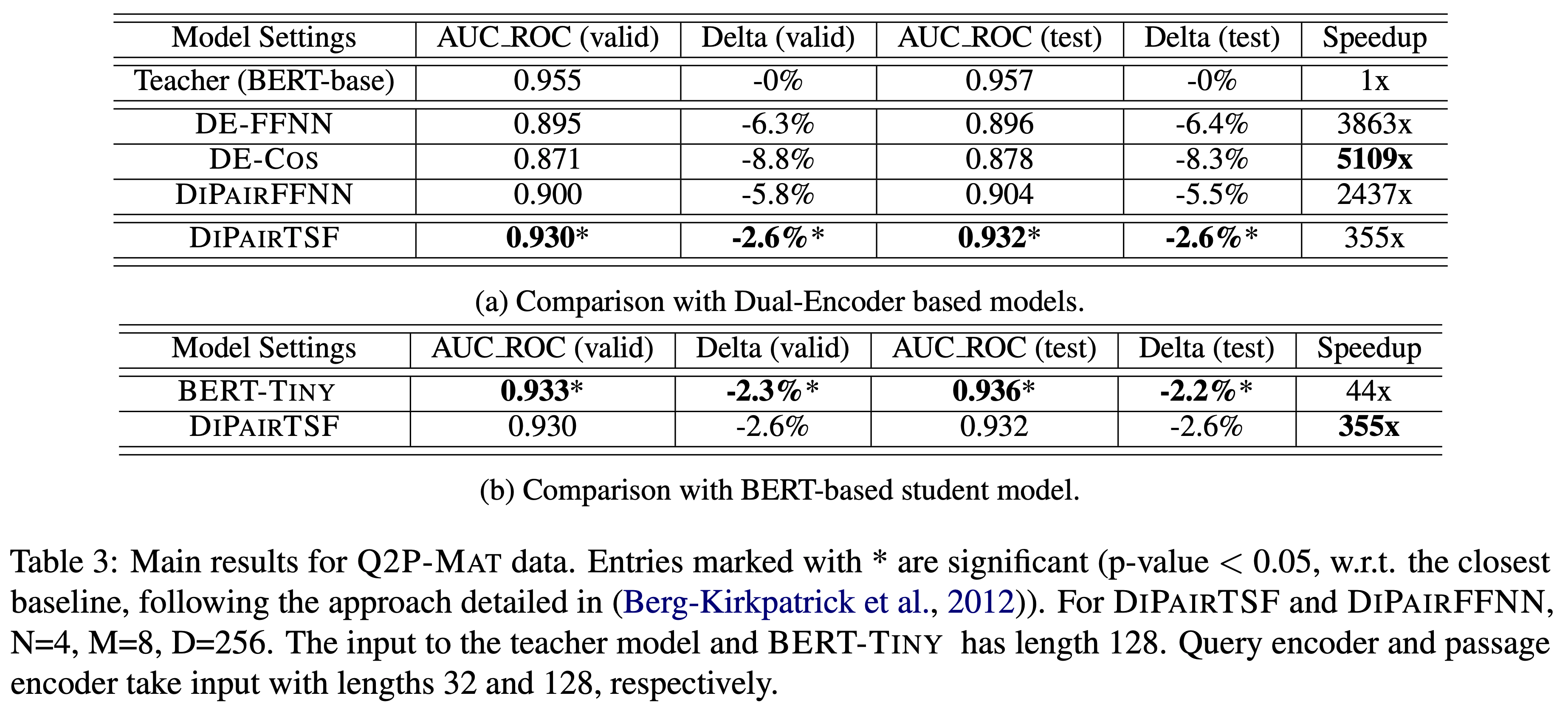
- Q2P-MAT is a binary classification task derived from the MSMARCO Passage Ranking data
- DiPiar + TSF 모델이 가장 좋은 성능을 보였으며, BERT-Tiny와는 비슷하지만 속도는 8배 빨랐음
- DE-Cos는 Dual-encoder 결과를 dot-product만 하기 때문에 속도는 매우 빨랐지만, input embedding 사이의 interaction이 충분치 않기 때문에 가장 안좋은 성능을 보임
Conclusion
In this work, we reveal the importance of customizing models for problems with pairwise/n-ary input and propose a new framework, DiPair, as an effective solution. This framework is flexible, and we can easily achieve more than 350x speedup over a BERT-based teacher model with no significant quality drop.

Joohong Lee
Machine Learning Researcher