Attentional Encoder Network for Targeted Sentiment Classification (arXiv 2019)
- 5 mins- Paper Link: https://arxiv.org/abs/1902.09314
- Author
- Youwei Song, Jiahai Wang, Tao Jiang, Zhiyue Liu, Yanghui Rao
- Sun Yat-sen University
- Published at
- arXiv 2019
Abstract
- Targeted sentiment classification (=aspect-based sentiment analysis) 문제는 특정 target에 대한 sentimental tendency를 맞추는 문제임
- 대부분의 previous approaches는 RNN과 attention을 기반으로 하고 있음
- 하지만, RNN은 병렬화가 어렵고, backpropagation through time (BPTT) 문제가 있어서 long-term pattern에 대해 기억을 유지하기 어려움
- 이런 문제를 해결하기위해, 우리는 Attentional Encoder Network (AEN)을 제안함. AEN은 recurrence를 피하고 context와 target을 모델링하기 위해 attention 기반 encoder를 도입했음
- 또한 우리는 label의 신뢰도 문제가 있음을 제기하고 이를 위한 label smoothing regularization 기법을 소개함
- 그리고 pre-trained BERT에 이런 것들을 적용하여 SOTA 성능을 얻었고 실험을 통해 모델의 effectiveness와 lightweight를 보임
1. Introduction
- Targeted sentiment classification는 fine-grained sentiment analysis task로서 문장에 나타난 특정 opinion target 단어의 sentiment polarity를 결정하는 문제임
- 예를 들어, “I hated their service, but their food was great.” 라는 문장이 있을 때, service 는 negative, food 는 positive의 polarity를 갖음
- Target은 보통 entity 혹은 entity aspect임
- 이전 연구의 첫번째 문제는 RNN에 굉장히 의존적이라는 것임. 때문에 RNN의 문제들이 살아있다는 것임
- 두번째 문제는 이전 연구들이 label unreliability issue를 간과하고 있다는 것임. neutral sentiment는 복잡한 sentimental state로서 모델의 학습을 어렵게 만듬. 우리가 알기론 이 분야에서 이런 이슈를 제기하는 것은 처음임
- 우리는 이런 문제를 attention encoder와 label smoothing regularization으로 해결하고자 함
- Pre-trained BERT를 사용하였으며, SOTA 성능을 보였고 기존 best RNN 모델보다 가벼움
- 우리의 main contribution은 다음과 같음:
- Target과 context words 간의 의미적 관계를 표현하기 위해 attentional encoder network를 디자인함
- Label unreliability issue를 처음으로 제기하고, 이를 해결하기 위해 label smoothing regularization term을 loss function에 추가함
- Pre-trained BERT를 이 태스크에 도입하였고, 일반 basic BERT보다 좋은 성능을 보이게 수정함. 최종 SOTA 성능을 얻음
- 다른 모델과 model size를 비교하므로서 제안하는 모델의 lightweight를 보임
2. Related Work
- pass
3. Proposed Methodology
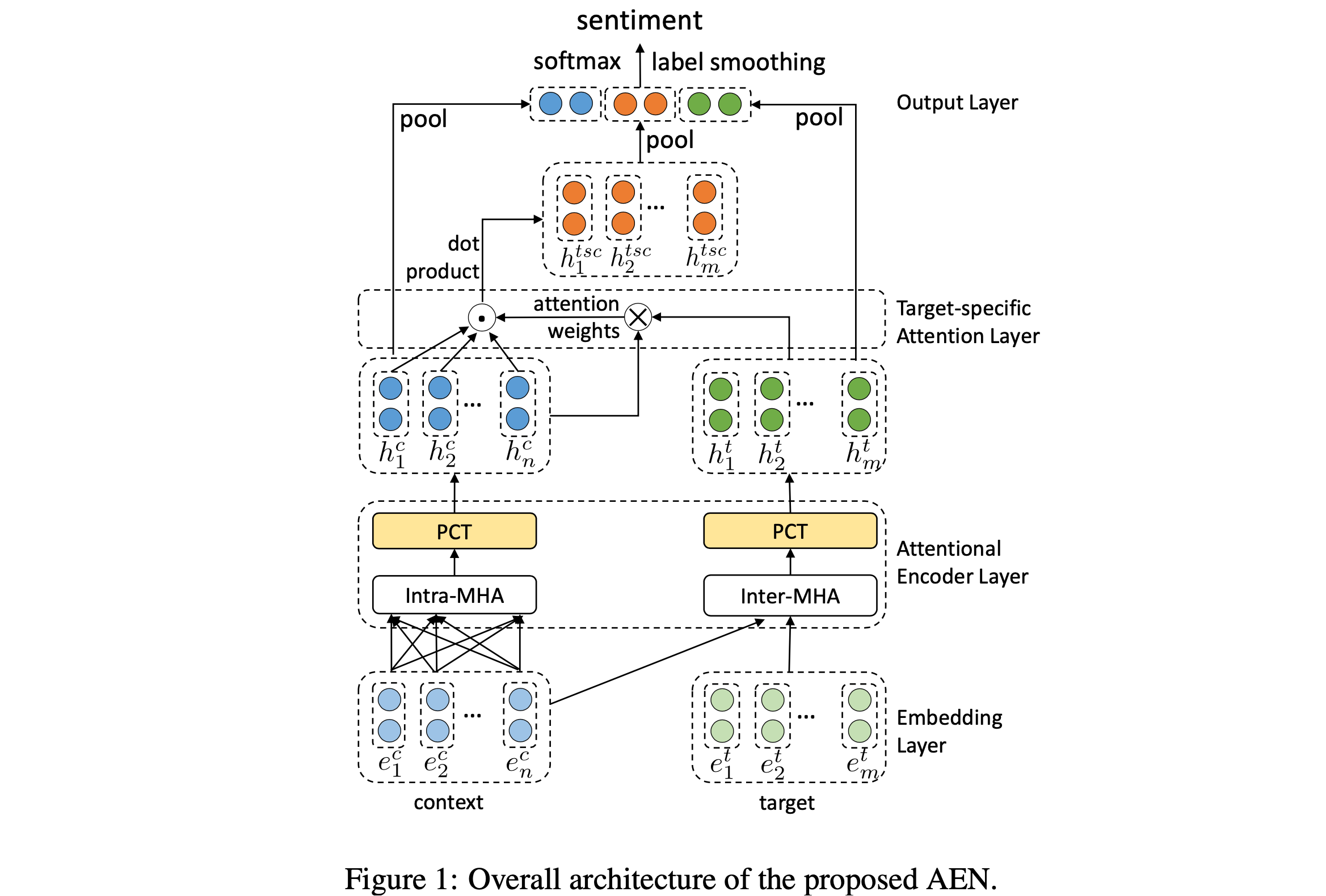
- w^c: context sequence
- w^t: target sequence, (subsequence of w^c)
- Figure 1이 proposed Attention Encoder Network (AEN)임
- embedding layer, attention encoder layer, target-specific attention layer, output layer 등으로 구성됨
- embedding layer에 GloVe embedding과 BERT embedding을 사용했으며, 이를 각각 AEN-GloVe, AEN-BERT라고 부름
3.1 Embedding Layer
3.1.1 GloVe Embedding
- pre-trained GloVe 사용함
3.1.2 BERT Embedding
- pre-trained BERT 사용함
- context는 “[CLS] + context + [SEP]”, target은 “[CLS] + target + [SEP]”로 만들어서 output word vectors of sequence를 얻었음
3.2 Attentional Encoder Layer
- LSTM을 대신해서 병렬처리가 가능한 attention 기반의 encoder layer로 대체함\
- 크게 Multi-Head Attention (MHA)와 Point-wise Convolution Transformation (PCT) 두가지 submodules로 구성됨
3.2.1 Multi-Head Attention
- Transformer (Vaswani et al., 2017) 의 Multi-Head Attention (MHA)를 차용함
- 약간 이를 변형해서 1) context words 자체적인 모델링을 위한 Intra-MHA와 target word를 2) context를 고려하여 모델링하기 위한 Inter-MHA를 사용함
- (변형했다고 하는데 딱히… 그냥 Intra-MHA는 self-attention이고, Inter-MHA는 일반 MHA로 보임)
3.2.2 Point-wise Convolution Transformation
- Transformer에서의 FFNN (1D convolution)을 말하는 것으로 보임
- 여기서는 이 convolutional layer를 2개 쌓아서 만듬
3.3 Target-specific Attention Layer
- 마지막으로 context와 target으로부터 얻은 hidden representation에 대해서 MHA을 한 번 더 거침
3.4 Output Layer
- 최종 아웃풋은 1) context repr, 2) target representation, 3) target-specific context repr, 각각을 average pooling한 결과를 concat하여 만듬
- 이에 대해서 마지막으로 classification layer를 하나 붙여서 최종 sentiment polarity distribution을 얻음
3.5 Regularization and Model Training
- neutral sentiment는 very fuzzy sentimental state이기 때문에, 학습 샘플 중 neutral 인 애들을 신뢰하기 어려움
- 그래서 우리는 Label Smoothing Regularization (LSR) term을 loss function에 추가하였음
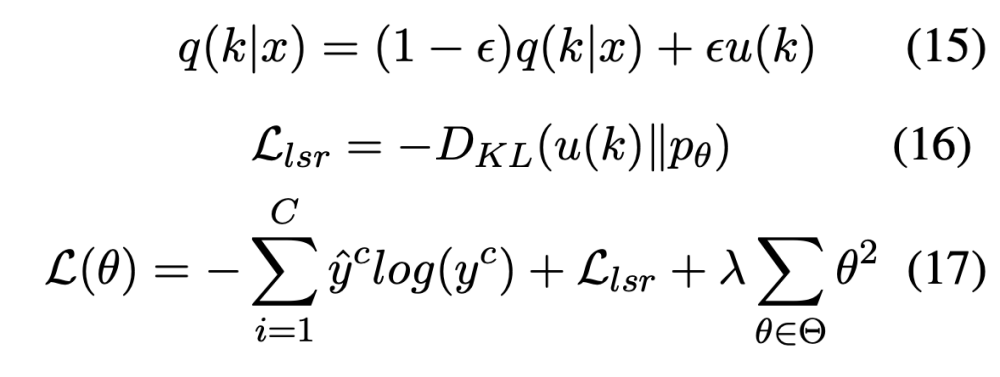
- 수식이랑 설명이 좀 이해하기 어렵긴한데 의미적으로 봤을 때, 기존 one-hot hard label과 u(k)를 가중합해서 target ground truth label을 만들겠다는 것임
- 예를 들어, 어떤 샘플이 [1, 0, 0]의 ground truth label을 갖고 있다고 했을 때, (1-eps) [1, 0, 0] + eps [1/3, 1/3, 1/3]을 해서 smoothing된 label을 만들어서 모델이 이를 target으로 학습하게 하겠다는 것임
- (위의 수식 전개가 완벽히 이 의미와 동치인지 모르겠음. 뭔가 수식이 틀린 느낌)
- L2-regularization term도 추가함
4. Experiments
4.1 Dataset and Experimental Settings
- SemEval 2014 Task 4 (LAP14, REST14) (Pontiki et al., 2014)
- TWITTER (Dong et al., 2014)
- 3가지 sentiment polarity: positive, negetive, neutral
- AEN-GloVe는 word embedding을 학습시 업데이트 하지 않았고, AEN-BERT의 경우 fine-tuning을 하였음
- 모든 weights는 Glorot initialization을 하였으며, LSR의 eps은 0.2를 주었음
- L2의 coefficient는 1e-5, dropout rate는 0.1을 주었음
- Adam 썼음
4.2 Model Comparisons
- None-RNN based baselines:
- Feature-based SVM (Kiritchenko et al., 2014)
- Rec-NN (Dong et al., 2014)
- MemNet (Tang et al., 2016b)
- RNN based baselines:
- TD-LSTM (Tang et al., 2016a)
- ATAE-LSTM (Wang et al., 2016)
- IAN (Ma et al., 2017)
- RAM (Chen et al., 2017)
- AEN-GloVe ablations:
- AEN-GloVe w/o PCT
- AEN-GloVe w/o MHA
- AEN-GloVe w/o LSR
- AEN-GloVe-BiLSTM (replaces the attentional encoder layer with two Bi-LSTM)
- Basic BERT-based model:
- BERT-SPC (feeds sequences “[CLS] + context + [SEP] + target + [SEP]” into the basic BERT model for sentence pair classification task)
4.3 Main Results
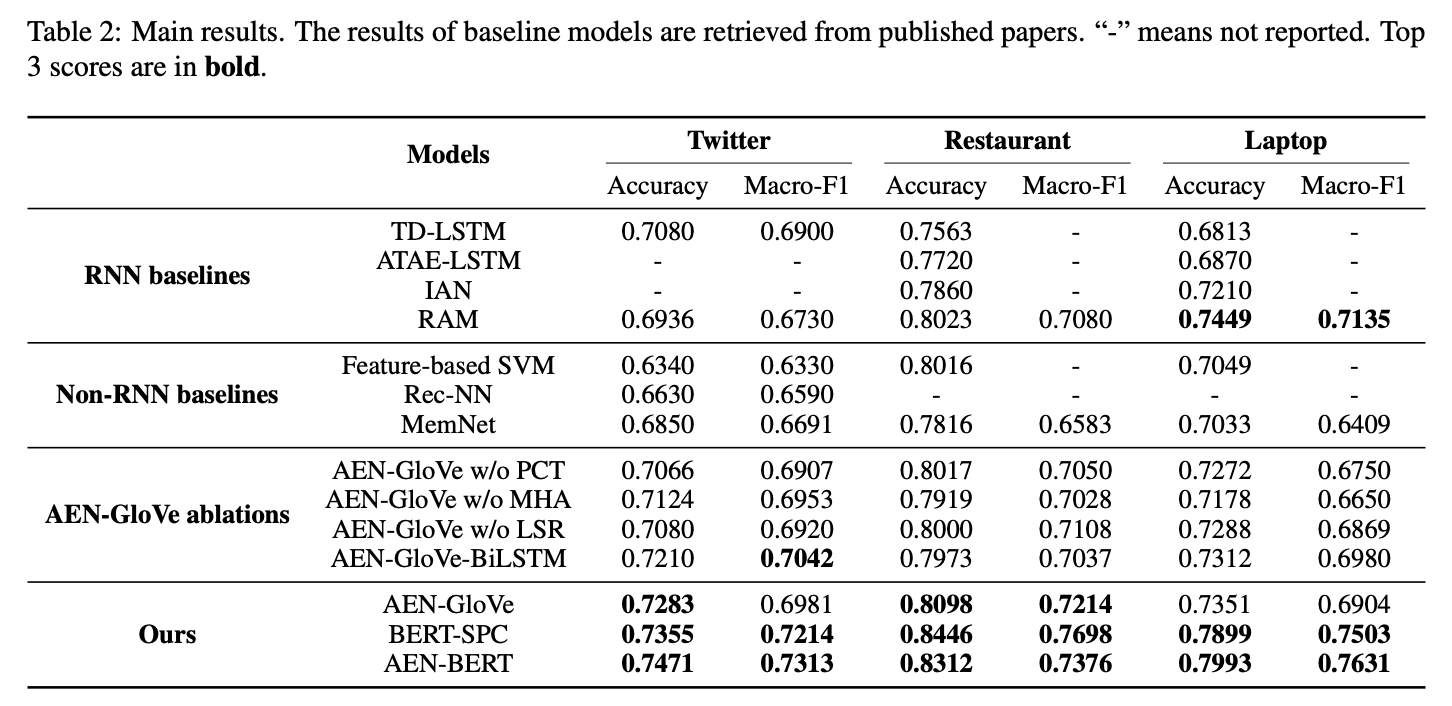
- 확실히 BERT를 기반으로 한 BERT-SPC와 AEN-BERT가 다른 모델 대비 아주 좋은 성능을 보였음
- 그중에서도 BERT-SPC보다 AEN-BERT가 성능이 좋았고, 이를 통해 BERT를 단순히 사용하는 것이 아니고 sepcific task에 맞춰서 customize할 필요가 있다는 것을 알 수 있음
- RAM이 다른 RNN baselines 보다는 성능이 좋았지만 small and ungrammatical text인 TWITTER에서는 잘 작동하지 않은 것으로 보아 Bi-LSTM이 이런 특성의 dataset에 대해 잘 작동하지 않는 것 같음
4.4 Model Analysis
- Table 2에서 AEN-GloVe의 결과를 보면 모든 component가 성능 향상에 좋은 영향을 준다는 것을 알 수 있음
- AEN-GloVe와 AEN-GloVe-BiLSTM은 전반적으로 거의 비슷한 성능을 보이고 있지만, AEN-GloVe의 파라미터 수가 더 적고 병렬화가 가능하다는 장점이 있음
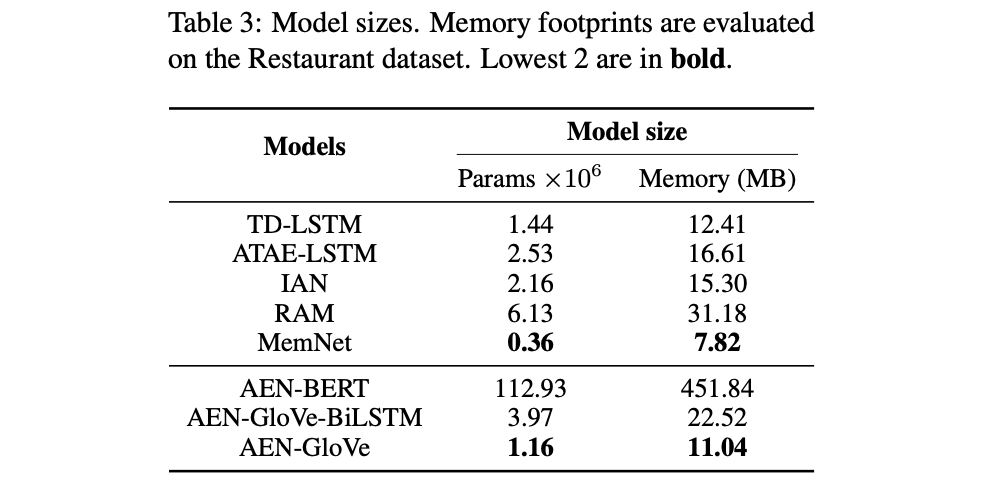
- 파라미터 사이즈와 메모리 크기에 대해서 비교해서 AEN이 좋음
- (메모리가 정확히 뭘 말하는 건지 모르겠음)
5. Conclusion
- Attentional encoder network를 제안함
- Attention 기반 encoder를 도입했고, label unreliability issue를 위해 LSR를 적용함
- 또한 pre-trained BERT를 ABSA 태스크에 도입하여 SOTA 성능을 보임
- 실험 및 분석을 통해 제안 모델의 effectiveness와 lightweight를 보임

Joohong Lee
Machine Learning Researcher