Aspect-based Sentiment Classification with Aspect-specific Graph Convolutional Networks (EMNLP 2019)
- 8 mins- Paper Link: https://www.aclweb.org/anthology/D19-1464/
- Author
- Chen Zhang, Qiuchi Li, and Dawei Song
- Beijing Institute of Technology
- Published at
- EMNLP 2019
Abstract
- Aspect-based sentiment classification 태스크에서 attention과 CNN을 많이 씀
- 하지만 이런 모델들은 relevant syntactical constraints와 long-range word dependency를 충분히 고려하지 못하고 있음
- 그래서 aspect sentiment의 판단에 대한 단서로 syntactically irrelevant한 contextual word를 택하는 문제가 생김
- 이런 문제를 해결하기 위해, dependency tree에 대해 Graph Convolutional Network (GCN)을 사용함. 이를 통해 syntactical information과 word dependency를 잘 사용하고자 함
- 구체적으로는 aspect-specific GCN이라는 모델을 제안함
- 3가지 벤치마크 데이터를 이용해 SOTA라는 것을 보였고, syntactical information과 long-range word dependency에 대한 문제가 잘 해결되었다는 것을 graph convolution structure를 통해 보임
1. Introduction
- Aspect-based (aka aspect-level) sentiment classification은 주어진 문장에서 나타난 aspect 단어의 sentiment polarity를 예측하는 문제임
- 예를 들어, “From the speed to the multi-touch gestures this operating system beats Windows easily.” 라는 문장이 있었을 때, aspect로 지정된 “operating system” 은 positive , “Windows” 는 negative 의 polarity를 갖음. 이걸 맞추는 문제임
- Limitation 1 of previous work
- Attention 기반의 RNN 모델들이 최근 좋은 성능을 보이고 있지만, 이들은 문장 내의 context word와 aspect 간의 syntactical dependency를 효과적으로 캡쳐링하기 어려움
- 즉, 현재의 attention mechanism 기반 모델들은 주어진 aspect가 문장에서 관련 없는 context word에 잘못 attending하게 할 수 있다는 것임
- 예를 들어, “Its size is ideal and the weight is acceptable” 이라는 문장에서 attention-based model은 종종 aspect인 size 의 descripor를 acceptable 이라고 보는 경우가 있음 (원래는 ideal 이 맞음)
- 이런 문제를 해결하기 위해, He et al. (2018) 은 attention weight에 syntactical costraint를 주려고 했으나, syntactical structure를 완전히 활용하지 못함
- Limitation 2 of previous work
- Attention 기반의 CNN 모델들은 aspect의 multi-word phrases을 위해 도입됨
- finding of Fan et al. (2018): sentiment of aspect는 보통 individual words가 아니고 key phrases에 의해 결정된다고 주장함
- 하지만 sentiment는 꼭 붙어있는 여러 단어에 의해 depict 되는 것이 아님. 따라서 인접한 연속된 word sequence를 multi-word feature로 쓰는 CNN은 위의 finding을 모델링하기 위한 방법으로 적절하지 않음
- 예를 들어, “The staff should be a bit more friendly.” 라는 문장이 있다고 했을 때, staff 라는 aspect에 대해서 CNN은 more friendly 를 key phrase로 보고 긍정적이라고 예측을 하는데 이는 올바르지 못함. 앞에 should be 가 있기 때문에 반대의 의미로 작용하고 따라서 부정으로 보는 게 맞음
- Attention 기반의 CNN 모델들은 aspect의 multi-word phrases을 위해 도입됨
- 우리는 위의 두 limitation을 해결하기 위해, dependency tree를 기반으로 한 GCN을 도입함. GCN은 syntactically relevant word를 잘 모델링할 수 있고 long-range multi-word relation과 syntactical infromation을 잘 활용할 수 있음. 또한 아직 이 분야에서 GCN은 제대로 사용된 적이 없음
- 우리의 contribution은 다음과 같음
- Aspect-based sentiment classification을 위해 syntactiacal dependency structure를 활용하는 방법을 제안하고 long-range multi-word dependency issue를 해결함
- 이를 위해 Aspect-specific GCN (ASGCN)이라는 novel architecture를 제안함. 우리가 알기론 이 분야에서 GCN은 우리가 처음 한 거임
- Syntactical information과 long-range word dependency를 leveraging하는 것의 중요성과 우리 모델이 이런 부분에 강점을 보인다는 것을 실험을 통해 보여줌
2. Background: Graph Convolutional Network
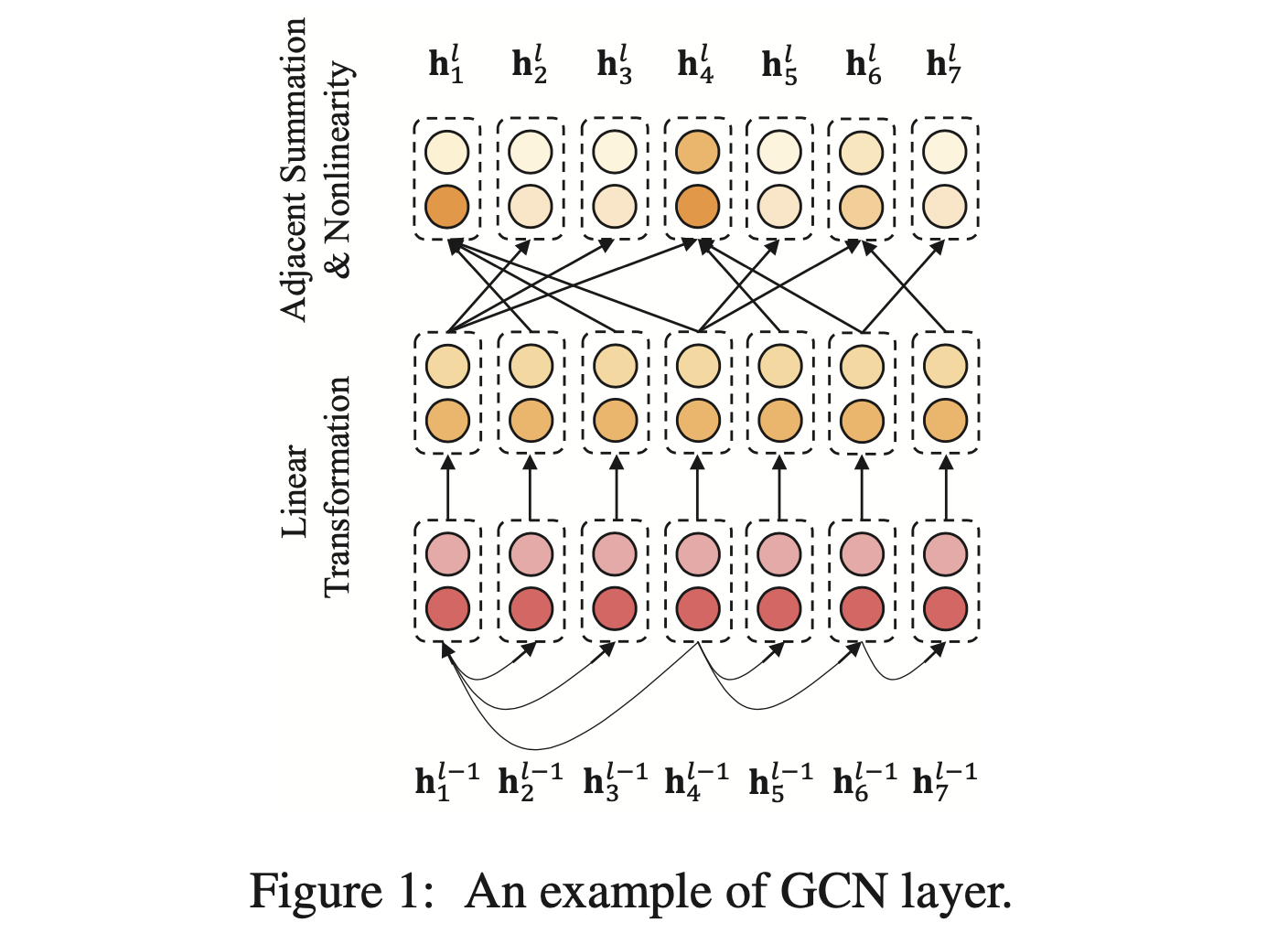
- GCNs은 local information만 보는 기존 CNNs의 확장판이라고 볼 수 있음. 단순히 인접한 word에 대한 convolution이 아니라, structural informaiton을 기반으로 한 convoluiton이라고 할 수 있음
- Graph convolution을 위해서는 우선 k 개(단어의 개수에 해당함)의 node에 대한 인접행렬 A (k x k) 이 필요함
- Graph convolution은 node representation을 다음과 같이 만듬:
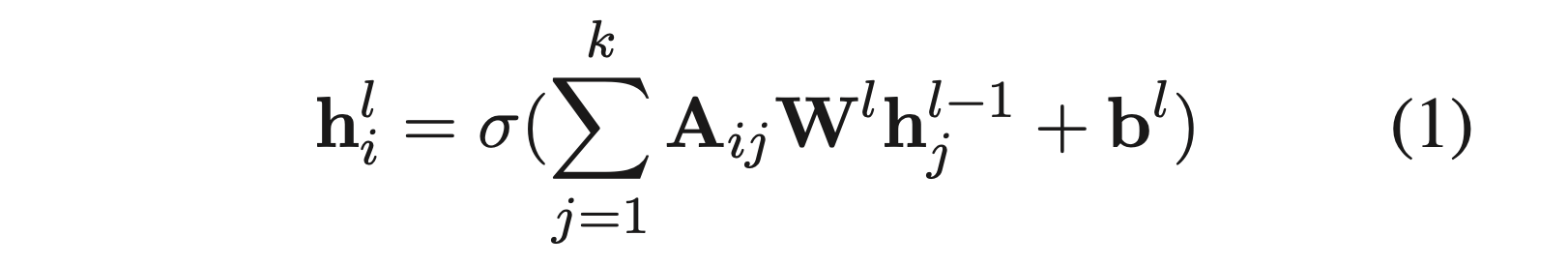
- W^l 은 linear transformation weight이고 b^l 은 bias term임. sigma는 non-linear function (ReLU)
- 간단히 기존 convolution layer를 A 를 기반으로 하는 것임. 기존 convolution은 A 의 연결 관계가 문장 상에서 인접한 단어에만 연결이 되었다고 보는 것임
- GCNs은 보통 위와 같은 graph convolutional layer를 쌓아서(stacking) 만듬. 이렇게 layer를 쌓으면 구조적으로 인접한 node에 서로 영향을 주면서 구조적 정보가 모델링되는 것임
- 문장에서 이런 구조적인 정보를 활용하기 위해 보통 dependency tree를 사용함
3. Aspect-specific Graph Convolutional Network
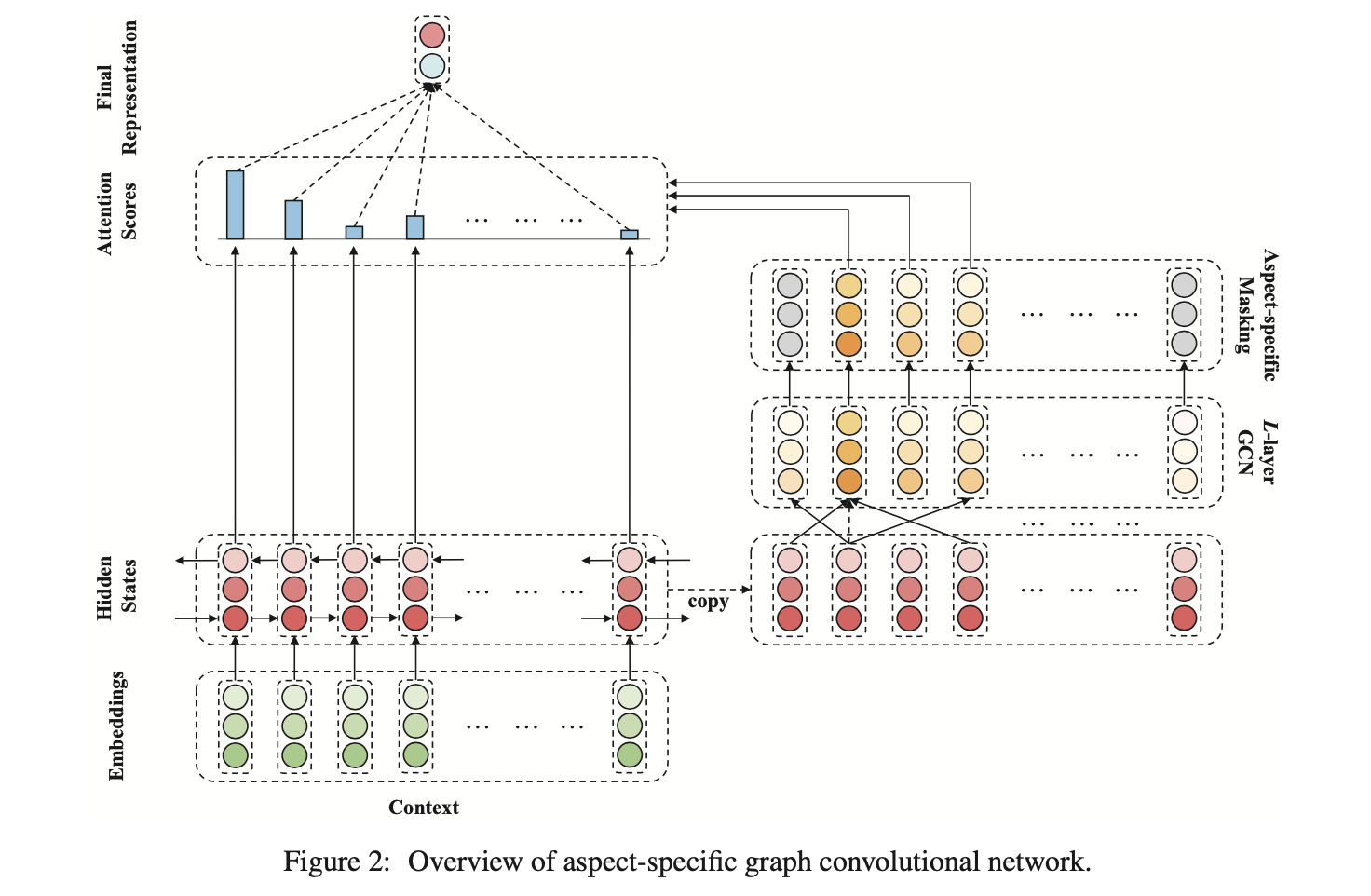
3.1 Embedding and Bidirectional LSTM
- Input 문장에 대해 word embedding 처리
- 그 다음 Bi-LSTM 태우고, output을 concat해서 최종 hidden representation을 만듬
3.2 Obtaining Aspect-oriented Features
- 일반적인 sentiment classification과 달리, ABSA는 타겟 aspect의 관점에서 sentiment classification을 해야 하고, 따라서 aspect-oriented feature extraction strategy가 필요함
- 이 연구에서 우리는 aspect-oriented feature를 얻기 위해 1) multi-layer graph convolution over the syntactical dependency tree를 적용하고, 2) aspect-specific masking layer를 맨 위에 붙였음
3.2.1 Graph Convolution over Dependency Trees
- 일단 graph convolution에 앞서, 주어진 문장에 대한 dependency tree를 만들어서 인접행렬 A 를 얻어야 함
- 우리는 이렇게 얻은 dependency tree를 기반으로한 ASGCN의 두가지 varient를 제안함
- ASGCN-DG
- Dependency tree를 un-directional graph로 바꿔서 사용하는 방법
- 보통 GCNs이 이렇게 graph를 만들어서 사용하곤 함
- ASGCN-DT
- 방향성을 그대로 유지해서 사용함
- Parent node가 children node의 영향을 폭넓게 받음
- ASGCN-DG
- 또한 Kipf and Welling (2017)이 제안한 self-looping을 적용함. self-looping이란 모든 node에 대해 self edge를 추가하여 loop를 만드는 방법으로, 인접행렬 A 의 대각 성분을 모두 1로 처리하는 기법임
- 이렇게 얻은 최종 A 를 기반으로 아래와 같이 graph convolution operation과 normalization을 통해 각 node의 representation을 update 해나감
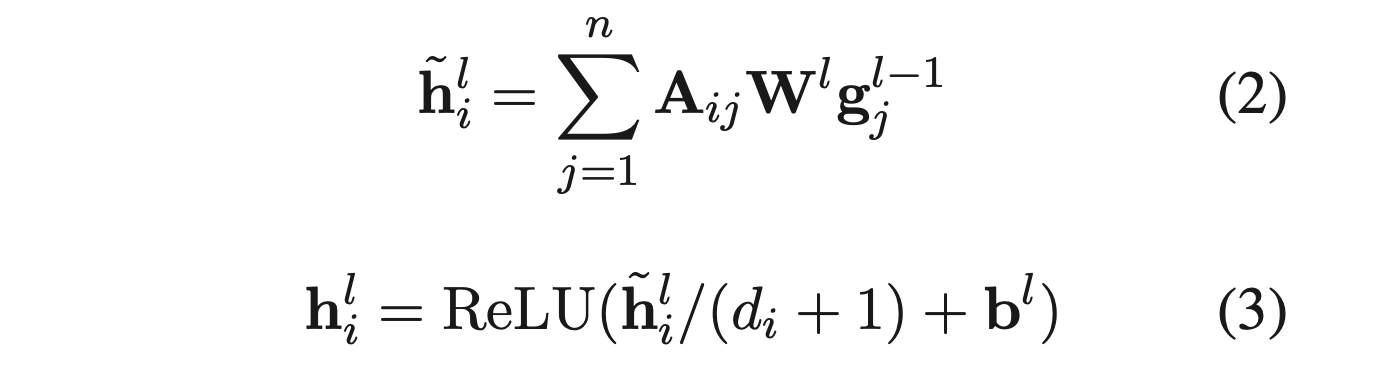
- Equation 2는 graph convoution 연산이고, Equation 3은 graph 상의 각 node의 degree를 기반으로 나눠주며 normalization을 하는 것임
- g^(l-1)_j 는 직전 GCN layer를 타고 나왔을 때의 j 번째 단어의 representation이고 h^l_j 는 현재 GCN layer가 만드는 것임
- d_i = sum^n_{j=1} (A_ij) 는 i 번째 토큰의 degree임
- W 와 b 는 trainable parameter
Position-aware Transformation (이해 잘 안됨)
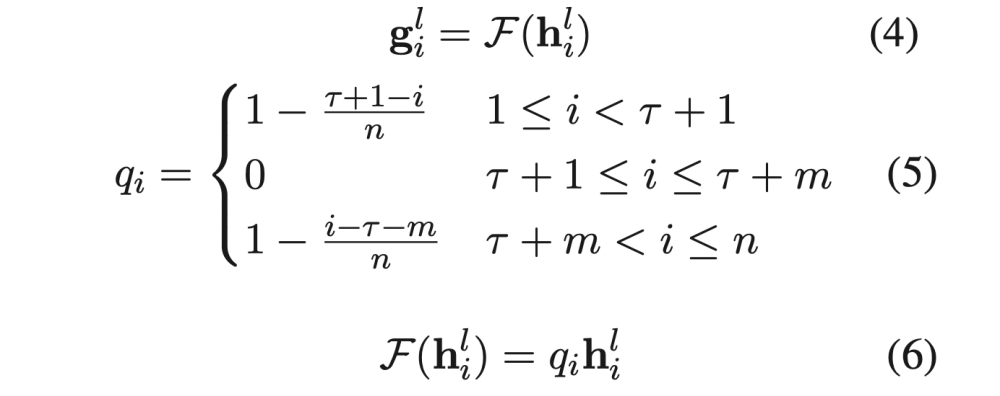
- 앞에서 얻은 graph convolution 연산의 결과인 h 에 대해 position-aware transformation을 함. Equation 4에서 함수 F가 이를 의미함
- F는 aspect 위치에 대한 각 단어의 상대 위치 정보를 기반으로 transformation하는 function인데, aspect에서 멀어질수록 영향력이 감소하도록 되어있음 (Equation 5)
- 이때 aspect 자체는 0을 곱하므로서 aspect 자체는 representation에 관여하지 못하고 contextual words에 대해서만 dependency structure를 기반으로 aspect representation을 형성하도록 함
3.2.2 Aspect-specific Masking
- GCN을 통해 얻게 된 h^L에 대해서 aspect-specific masking 처리를 함
- 간단히 aspect 단어를 제외한 모든 단어에 zero-masking을 하는 것임
- 이를 통해 H^L_mask 를 얻음
3.3 Aspect-aware Attention
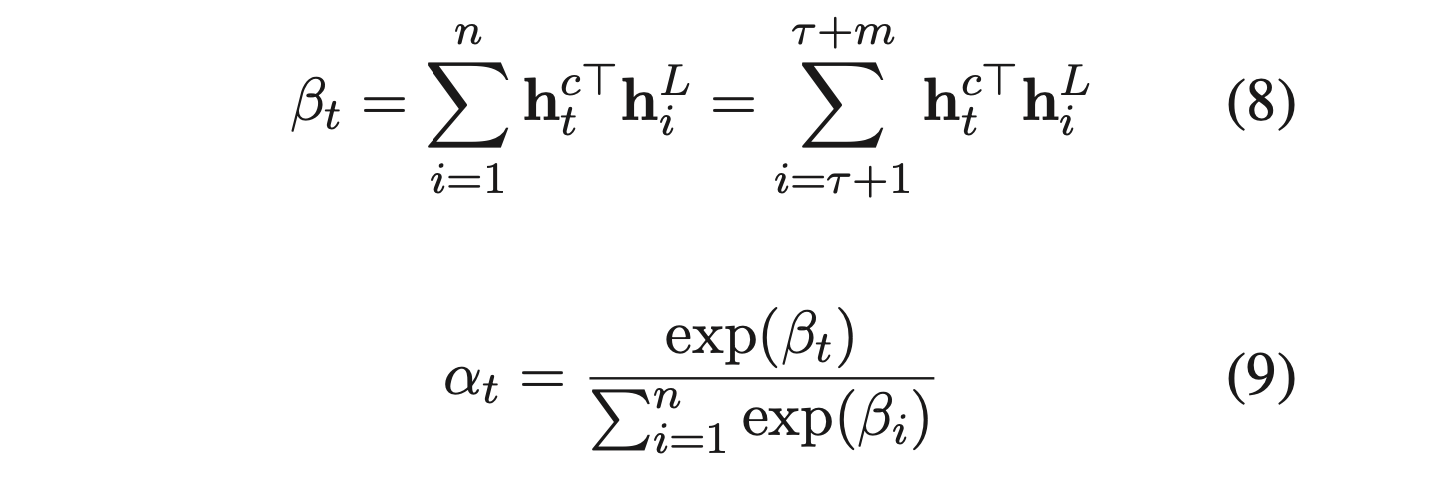
- 앞에서 GCN을 통해 구한 aspect의 representation h^L 와 Bi-LSTM의 output h^c 의 attention을 통해서 최종 representation을 만듬
- h^L 은 앞에서 zero-masking을 했기 때문에 aspect 위치의 단어들만 살아있는 상태임
- 이 aspect 단어들과 문장의 각 단어(h^c_t) 간의 dot-product의 합들에 대해서 attention을 취함
- 그렇게 구한 alpha에 대해서 h^c 를 가중합하여 최종 representation r 을 구함
3.4 Sentiment Classification
- r 에 대해 linear 하나 붙여서 최종 classification
3.5 Training
- standard gradient descent
- Cross-entropy loss와 L2-regularization 사용
4. Experiments
4.1 Datasets and Experimental Settings
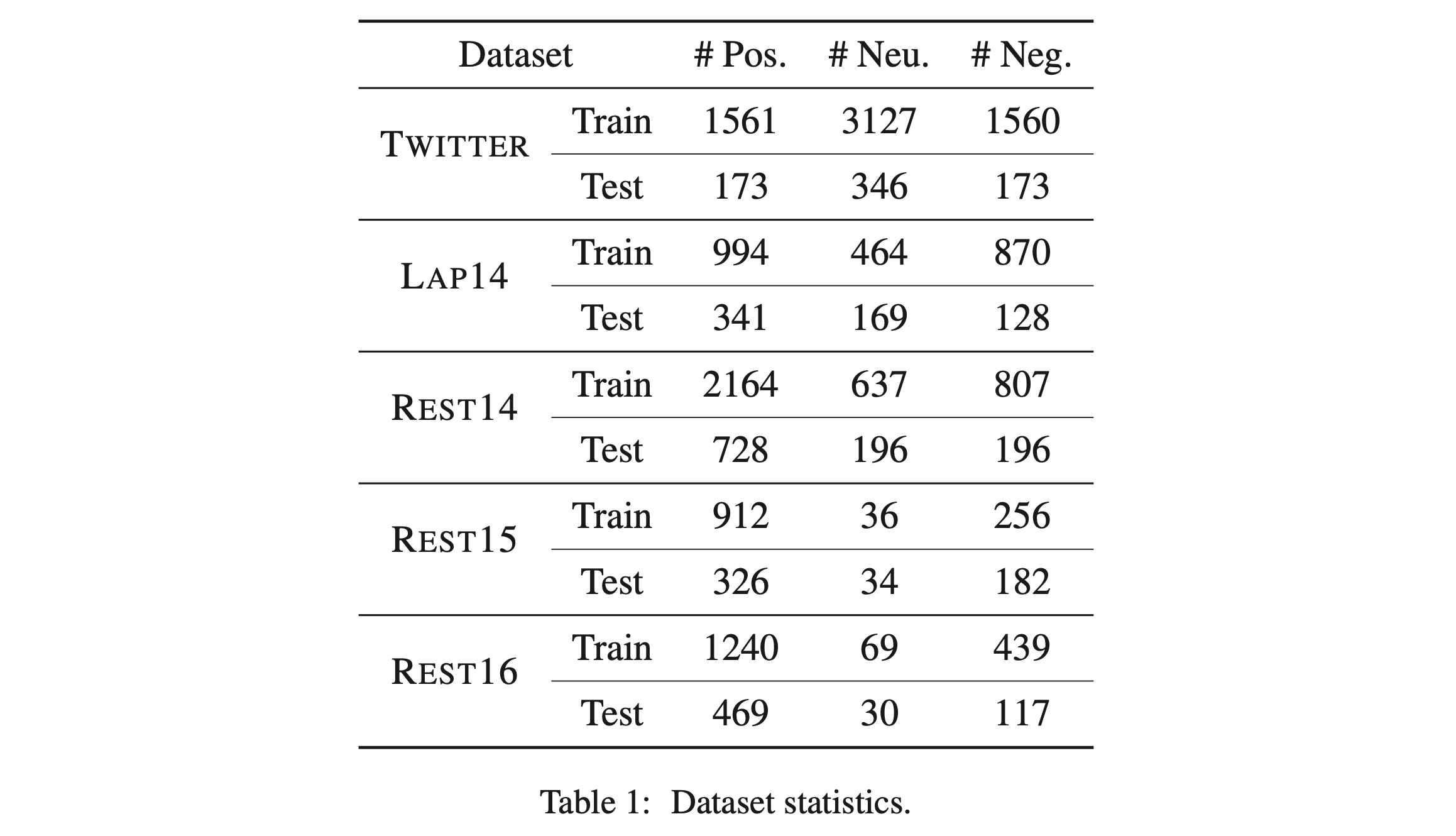
- 5개의 dataset을 사용
- TWITTER (Dong et al., 2014)
- SemEval 2014(LAP14, REST14), 2015(REST15), 2016(REST16) dataset
- 이전 연구 (Tang et al., 2016b) 처럼 conflicting polarity 샘플과 aspect가 없는 sentence를 제거하였음
- 각 데이터셋 별 label 분포:
- GloVe, Adam 사용함
- learning rate = 1e-3
- coefficient of L2 = 10^5
- batch size = 32
- # of GCN layer = 2
- 실험 결과(Acc, F1)는 random init하여 3번 돌린 결과의 평균임
4.2 Models for Comparison
- SVM (Kiritchenko et al., 2014)
- LSTM (Tang et al., 2016a)
- MemNet (Tang et al., 2016b)
- AOA (Huang et al, 2018)
- IAN (Ma et al., 2017)
- TNet-LF (Li et al., 2018)
- ASCNN: 자체적으로 ASGCN 모델에서 GCN대신 CNN을 사용하여 만듬
4.3 Results
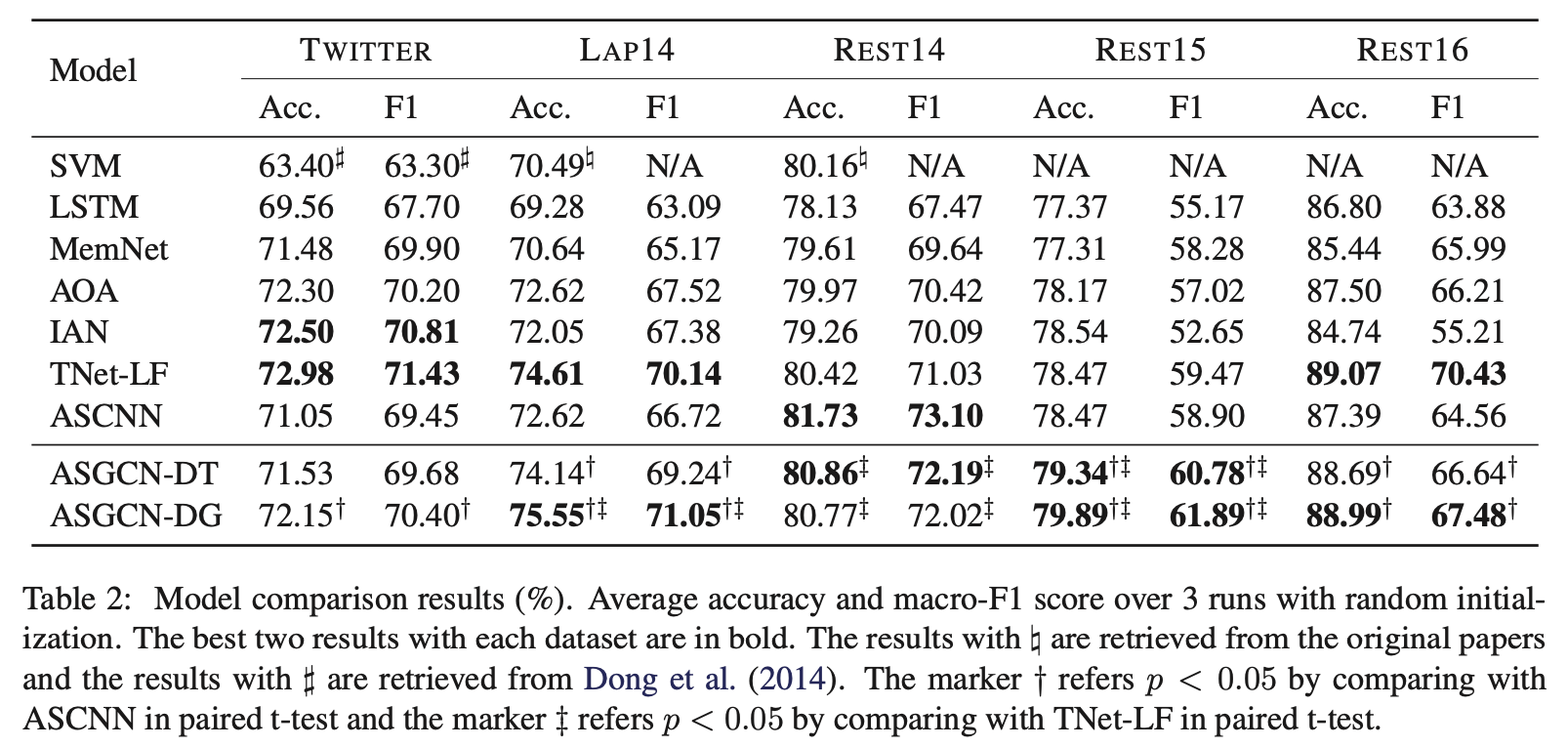
- 제안하는 ASGCN이 SOTA 혹은 baseline(TNet-LF)에 대해 comparable한 성능을 보임
- ASGCN-DG가 DT보다 TWITTER, LAP14, REST15, REST16에 대해서는 꽤 차이를 벌리며 outperform했음
- ASCNN에 비해서 ASGCN이 REST14를 제외한 모든 dataset에서 좋은 성능을 보였는데, 이를 통해 long-range word dependency를 ASGCN이 더 잘 잡아내고 있다는 것을 알 수 있음
- 우리는 REST14와 TWITTER의 문장들이 not so sensitive to syntactic infromation이며, less grammatical하다고 의심 중. 그래서 우리 모델이 baseline보다 조금 부족한 성능을 얻지 않았을까 싶음
4.4 Ablation Study
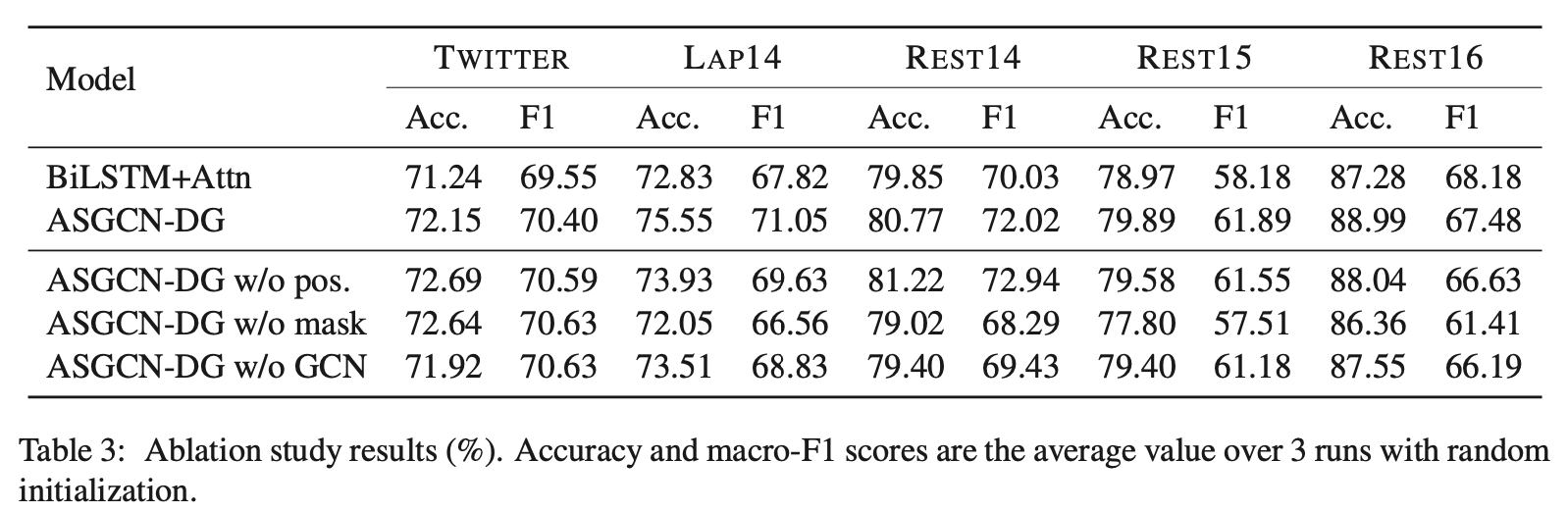
- w/o pos: removal of position weights
- w/o mask: rid of aspect-specific masking
- w/o GCN: perserving position weights and aspect-specific masking, but without using GCN layers
4.5 Case Study
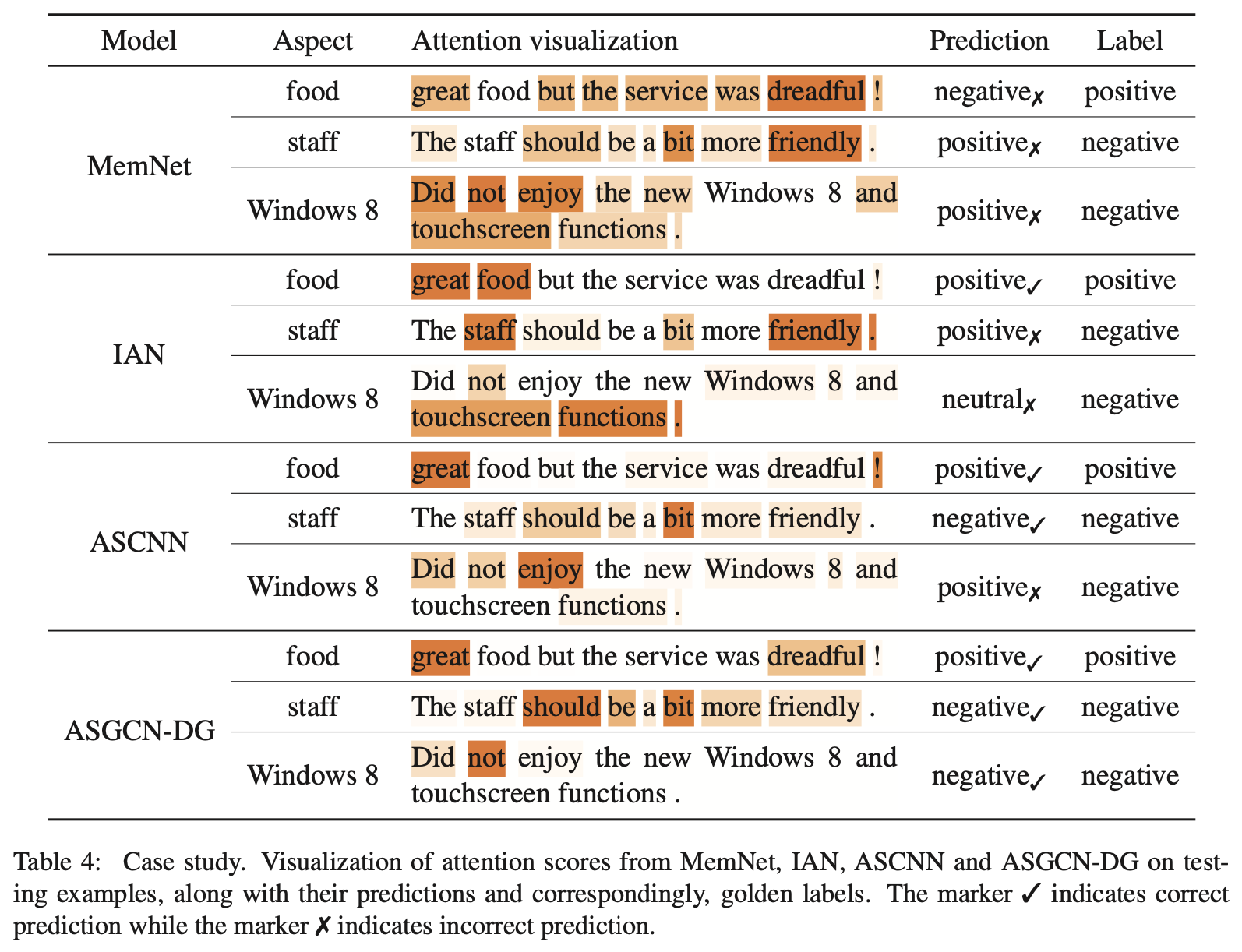
- Attention visualization을 통해 baseline 모델들과 비교를 해보았음
- First sample: “great food but the service was dreadful!”
- Aspect가 food, service 로 한 문장에 두 개의 aspect가 나타난 케이스임
- Second sample: “The staff should be a bit more friendly.”
- Aspect는 staff 이고, should 에 의해 문장의 의미가 역전되는 케이스임
- Third sample: “Did not enjoy the new Window 8 and touchscreen function.”
- Aspect는 Window 8 이고, 부정어(negation) not 이 등장하는 케이스임
- ASCNN은 local에 집중하기에 2번째 케이스에서 staff 근처에 있는 should 에 잘 집중하여 정답을 맞추었지만, longer-rage word dependency를 잘 처리하지 못해서 3번째 케이스에서는 정답을 맞추지 못함
- ASGCN은 위의 모든 케이스를 다 잘 맞춤
5. Discussion
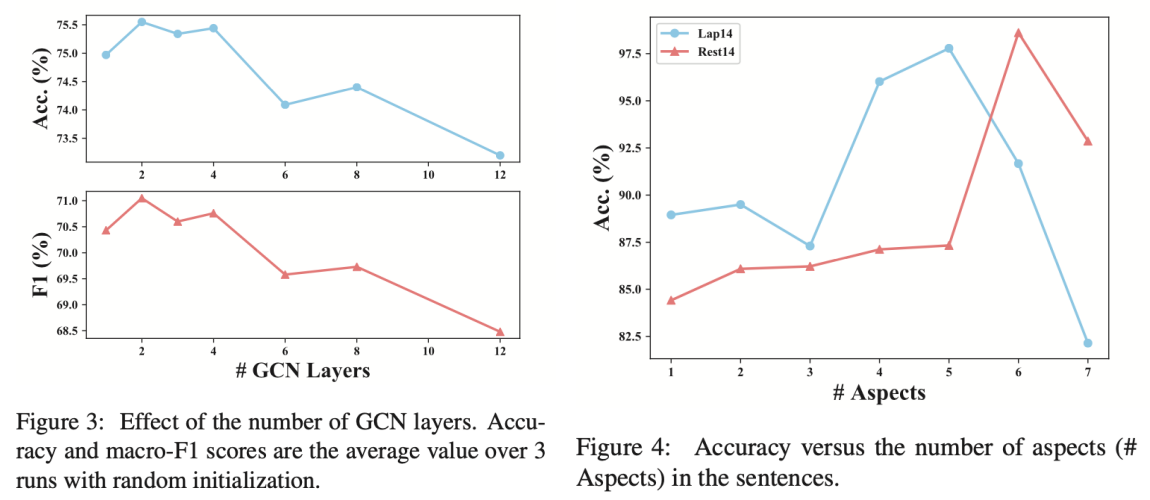
5.1 Investigation on the Impact of GCN Layers
- GCN layer의 개수는 2개일 때 가장 좋고 늘어날수록 성능이 떨어짐
5.2 Investigation on the Effect of Multiple Aspects
- 한 문장에 여러 개의 aspect가 나타날 수 있음
- Aspect의 개수에 따라 dataset을 나눠서 학습하고 평가해봄
- 1개부터 7개까지 실험을 해보았고, 8개 이상은 샘플 수가 너무 적어서 안했음
- 한 문장에서 aspect의 수가 3개 이상부터는 성능 변동폭이 커지는 걸 볼 수 있는데, low robustness in capturing multiple-aspect correlation을 보여준다고 할 수 있음
- 이런 부분(multi-aspect dependency)을 future work에서 개선할 필요가 있음
6. Related Work
- 생략
7. Conclusions and Future Work
- 우리는 ABSA를 위한 현재 나온 모델들이 당면한 challenges를 재검토하고 GCN이 이런 부분을 tackling하기 적합하다는 것을 보였음
- GCN을 ABSA 문제에 맞춰서 수정하여 novel network인 ASGCN을 제안함
- 실험을 통해 GCN이 syntactiacl infromation과 long-rage word dependency를 leveraging하면서 전반적인 성능 이득을 가져왔다는 걸 보임
- 아직 이번 연구에서는 dependency tree의 edge 정보를 활용하지 않았음
- 우리는 이런 edge 정보를 활용한 graph neural network를 디자인해볼 계획임
- 또한 domain knowledge를 사용하는 것도 고려하고 있음
- 마지막으로 지금은 multiple aspect여도 하나의 aspect에 대해서만 예측을 하고 이를 여러번 하는 건데, 추후에 aspect들 간의 dependency를 포착하여 동시에 multiple aspect의 sentiment를 예측하는 ASGCN의 확장판을 고려 중임

Joohong Lee
Machine Learning Researcher