Adaptive Input Representations for Neural Language Modeling (ICLR 2019)
- 4 mins- Paper Link: https://arxiv.org/abs/1809.10853
- Author
- Alexei Baevski & Michael Auli
- Facebook AI Research
- Published at
- ICLR 2019
Abstract
- Language modeling을 위한 adaptive input representations을 제안
- Grave et al. (2017)이 제안한 adaptive softmax를 input representation으로 확장함
- Input과 output layer를 어떻게 factorize할지, 그리고 words, characters, sub-word units을 어떻게 모델링할지에 대한 몇가지 선택지가 있는데, 이중 self-attentional architecture에서 많이 쓰는 방법들을 비교해봄
- 실험을 통해 adaptive embedding이 많이들 쓰는 character input CNN 보다 더 적은 parameter를 사용하면서도 2배 이상 빠르다는 결과를 얻었음
- WikiText-103 benchmark에서 기존 SOTA를 10 이상 개선한 18.7의 perplexity를 얻었고, Billion Word menchmark에서는 23.02의 perplexity를 기록함
1. Introduction
- 논문에서 제안하는 adaptive input embeddings (representations) 는 adaptive softmax (Grave et al., 2017)을 input word representations로 확장한 것임
- Adaptive softmax (Grave et al., 2017): output word embeddings에서 빈도수가 높은 단어에 더 많은 parameter 할당하고 적으면(희귀하면) 덜 할당하는 variable capacity scheme을 제안함
- 간단히 빈도수가 높은 단어에 더 많은 capacity를 부여하고 낮은 단어는 capacity를 줄이는 것이고, 이를 통해 희귀한 단어에 대한 overfitting을 완화할 수도 있음
- Adaptive input embeddings을 input과 output layer에 적용했을 때 parameter 수를 23% 감소시킬 수 있었고 fixed size embeddings에 대해서 더 높은 accuracy를 얻음
- 게다가 Adaptive input representations을 output의 adaptive softmax와 weight tying을 하면 61%나 parameter를 감소시킬 수 있음
- Abstract에 언급한 것처럼 많은 성능 향상을 보임
2. Related Work
- pass
3. Adaptive Input Representations
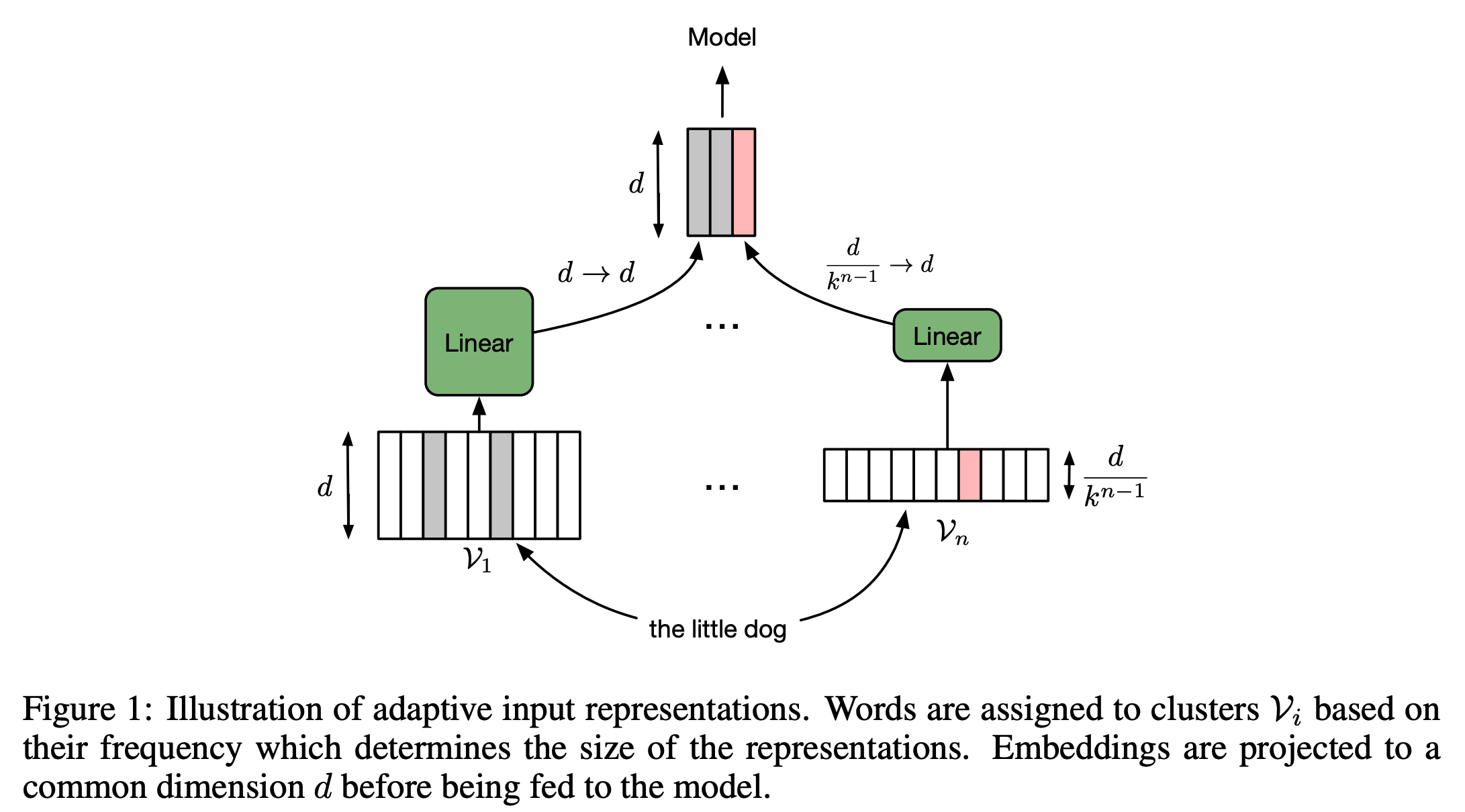
- 먼저 a number of clusters that partitions the frequency ordered vocabulary $\mathcal{V}$을 정의함
- $\mathcal{V} = \mathcal{V_1} \cup \mathcal{V_2}, …, \mathcal{V_{n-1}} \cup \mathcal{V_n}$ such that $\mathcal{V_i} \cap \mathcal{V_j} = \emptyset$ for $\forall i, j$, and $i \neq j$
- $\mathcal{V_1}$은 most frequent words의 집합이고, $\mathcal{V_n}$은 least frequent words의 집합
- Capacity를 줄이기 위해 각 cluster에 대해서 factor $k$를 이용해서 embedding dimension을 줄임
- $\mathcal{V_1}$의 embedding dimension은 $d$, $\mathcal{V_n}$의 dimension은 $\frac{d}{k^{n-1}}$
- 보통 $k$는 Grave et al. (2017)을 따라 4를 씀
- 그 다음, linear projections $W_1 \in \mathbb{R}^{d \times d}, …, W_n \in \mathbb{R}^{d/k^{n-1} \times d}$를 사용하여 각 cluster의 embeddings을 동일한 $d$ dimension으로 매핑하여 concat함 (이후 모델 input에서 편하게 사용하기 위함)
- Figure 1이 해당 과정을 잘 표현하고 있으며, 이미 $d$차원인 $\mathcal{V_1}$도 마찬가지로 같은 $d$ 차원에 projection을 함
- 정리하자면, input words에 대해서 1) 각 단어를 빈도에 따라 cluster에 맞게 partitioning을 하고, 2) 해당 cluster의 embedding lookup을 한 뒤, 3) 모두 동일하게 $d$ 차원으로 projection하고 원래의 순서에 맞게 concat함
Weight sharing
- Output layer에 adaptive softmax를 적용하였고, $\mathcal{V}$의 partitions, $d$, $k$이 동일하다면 weight tying (Inan et al., 2016; Press & Wolf, 2017)을 할 수 있음
- Tying까지하면 parameter 수는 더욱 감소하고 성능도 향상됨
- WikiText-103에서는 embedding, projection 둘 다 공유할 때 가장 좋았고, Billion Word는 embedding만 공유할 때 가장 좋았음
4. Experiments Setup
4.1. Model
- Transformer (Vaswani et al., 2017) decoder를 약간 변형해서 사용
- Block 16개를 쌓았으며, layer normalization을 self-attention과 FFNN 전에 붙였음 (원래 해당 layer 다음에 붙음)
4.2. Datasets
- WikiText-103: 100M tokens and 약 260K vocab
- Billion Word: 768M tokens and 약 800K vocab
4.3. Batching
- pass
4.4. Input and Output Layer Hyperparameters
Embedding size
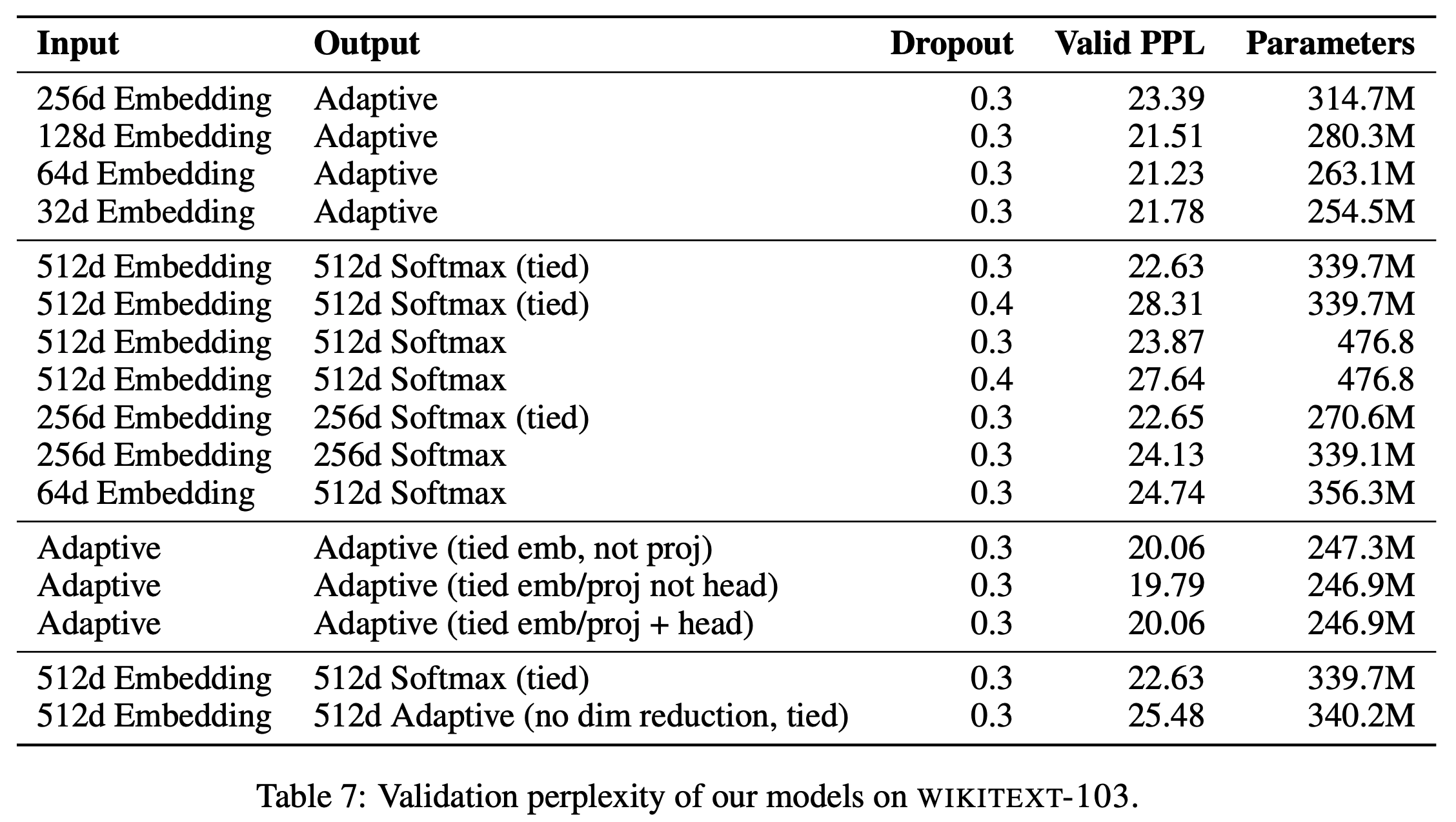
- Fixed size word input layers and softmax output layers의 embedding size는 보통 512를 사용함
- Fixed input and adaptive softmax는 Billion Word에서는 256, WikiText-103에서는 64의 embedding size를 사용함
- 이에 대한 실험은 Figure 7을 참고
Character CNN
- Kim et al., (2015)의 character input modeling 방법을 사용함
Adaptive input representations and adaptive softmax
- Adaptive word inputs and adaptive softmax를 위해서 embedding size $d=1024$, reducing factor of $k=4$를 사용함
- Cluster는 3개로 하였고, 따라서 $d=1024$, $d=256$, $d=64$의 차원을 각 cluster가 사용함
- WikiText-103은 cluster $\mathcal{V}_1, \mathcal{V}_2, \mathcal{V}_3$을 20K, 40K, 200K의 vocab size로 세팅함
- Billion Word는 60K, 100K, 640K로 세팅함
Sub-word models
- BPE는 각 데이터셋에 대해서 vocab size를 32K로 학습을 시킴
- Input/output의 embedding size는 1024로 하였고, 단어의 확률은 sub-word units의 곱으로 처리하였음
Optimization
- Nesterov’s accelerated gradient method (Sutskever et al., 2013)을 사용함
- WikiText-103은 286K step 학습
- Billion Word는 975K step 학습
5. Experiments
5.1. Main Results
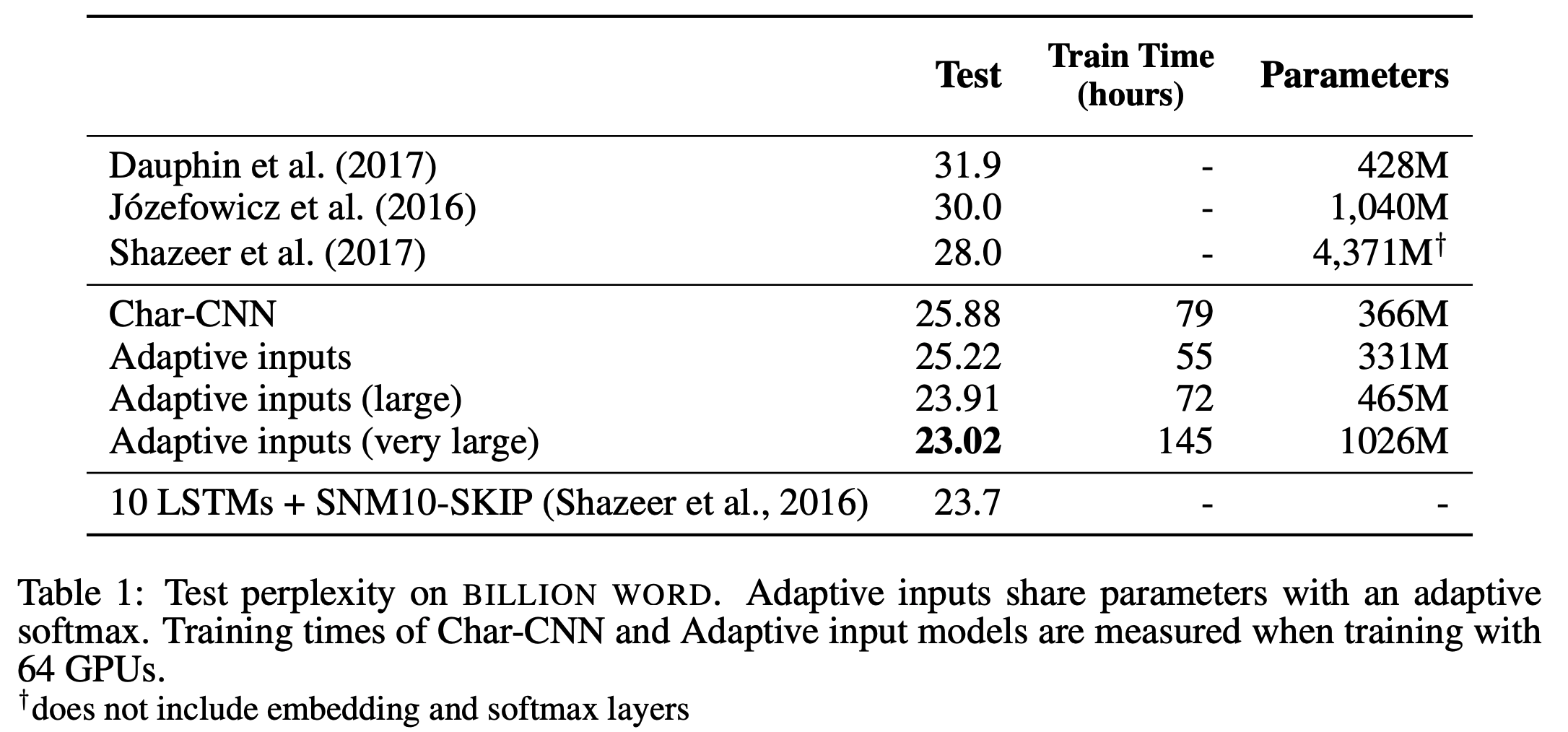
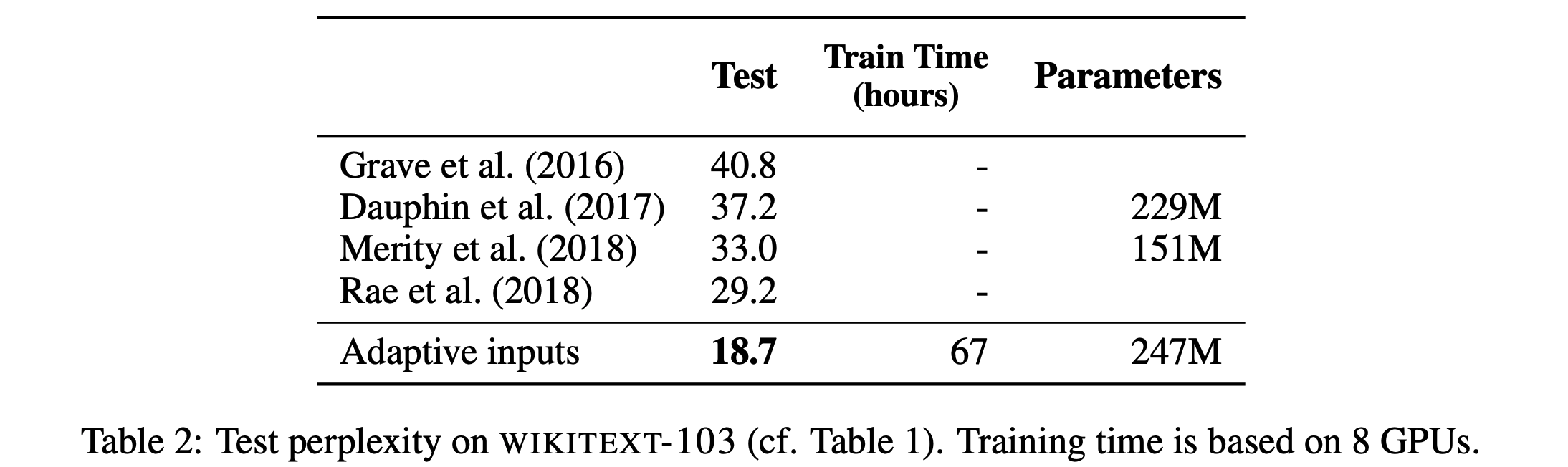
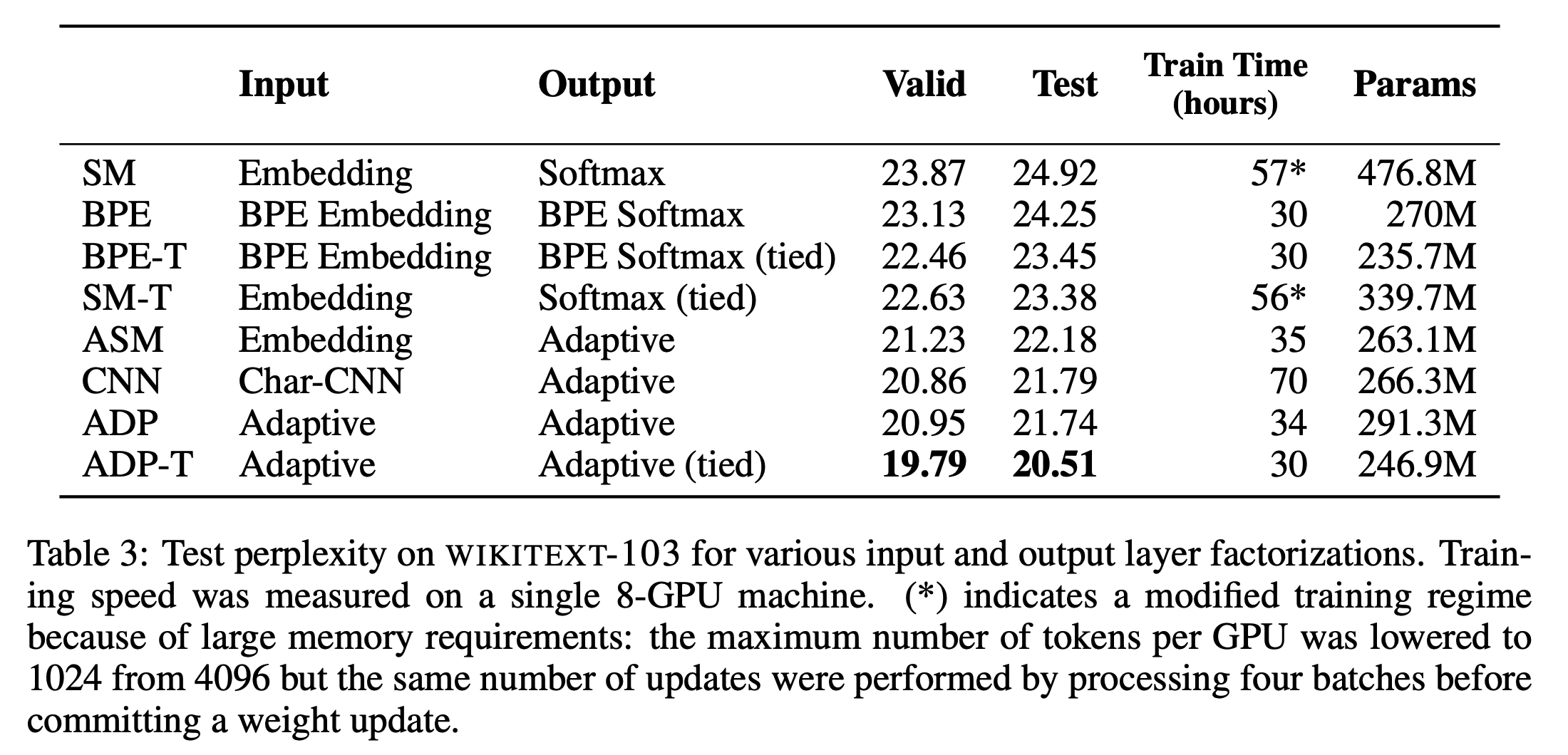
5.2. Comparison of Input and Output Layer Factorization
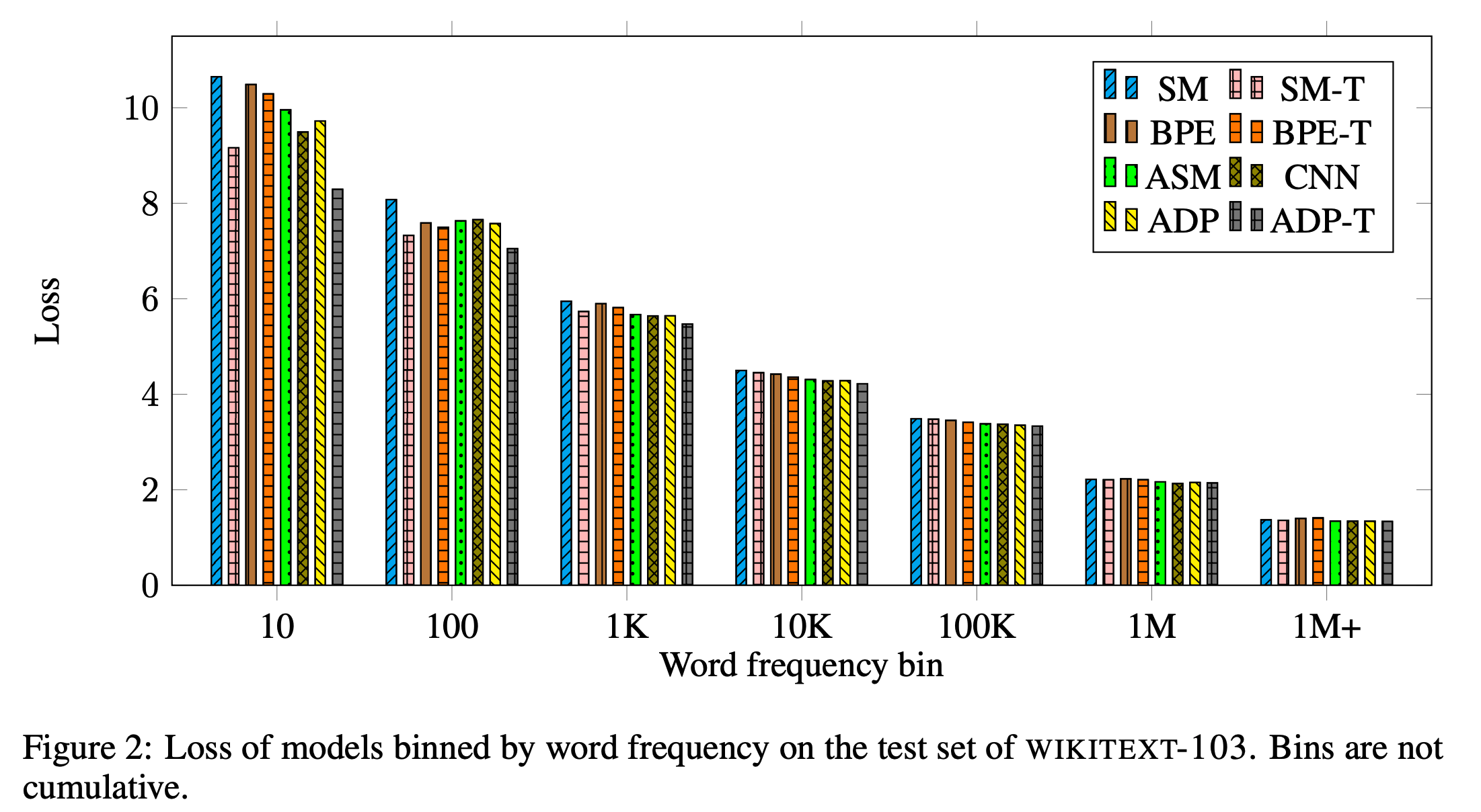
5.3. Analysis
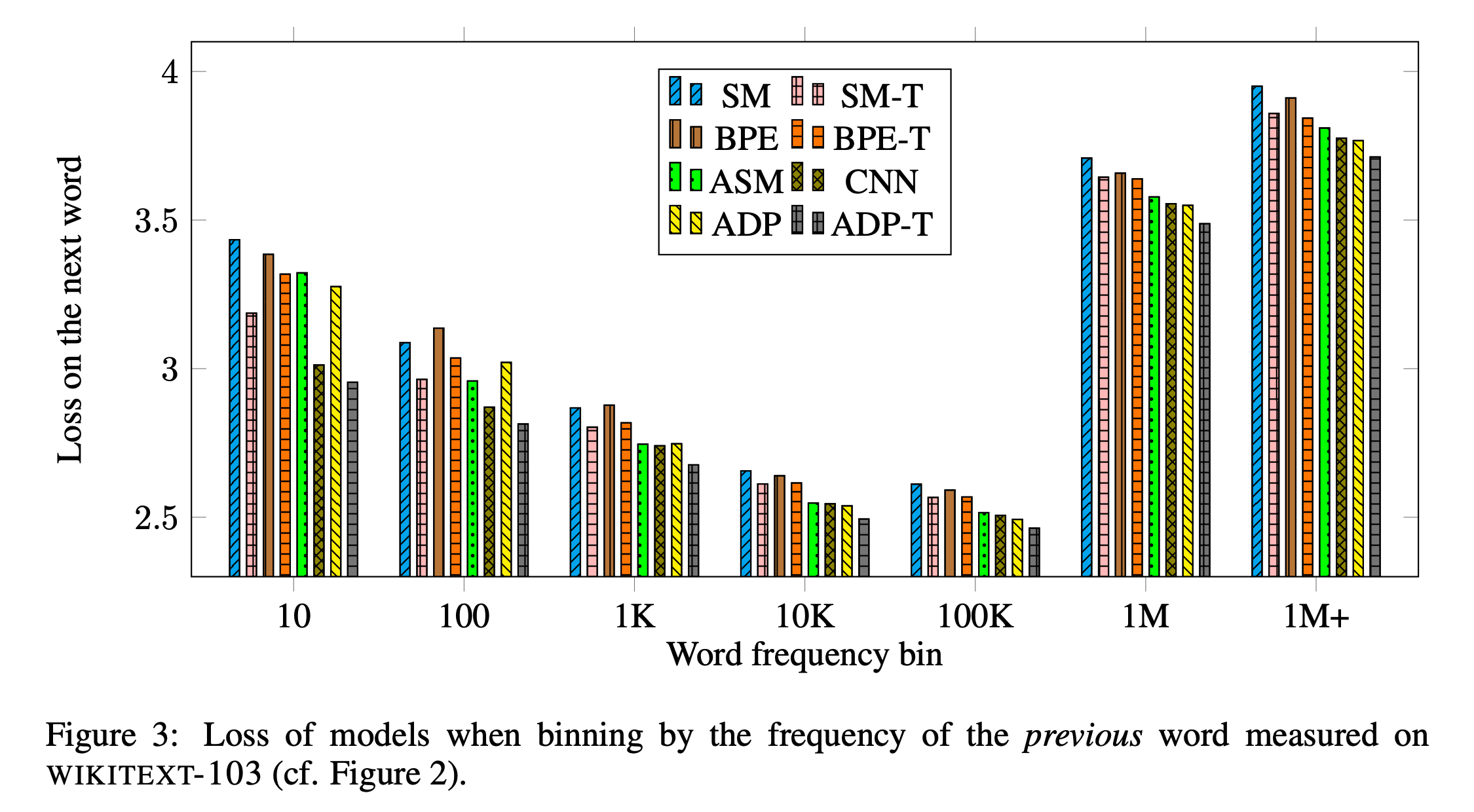
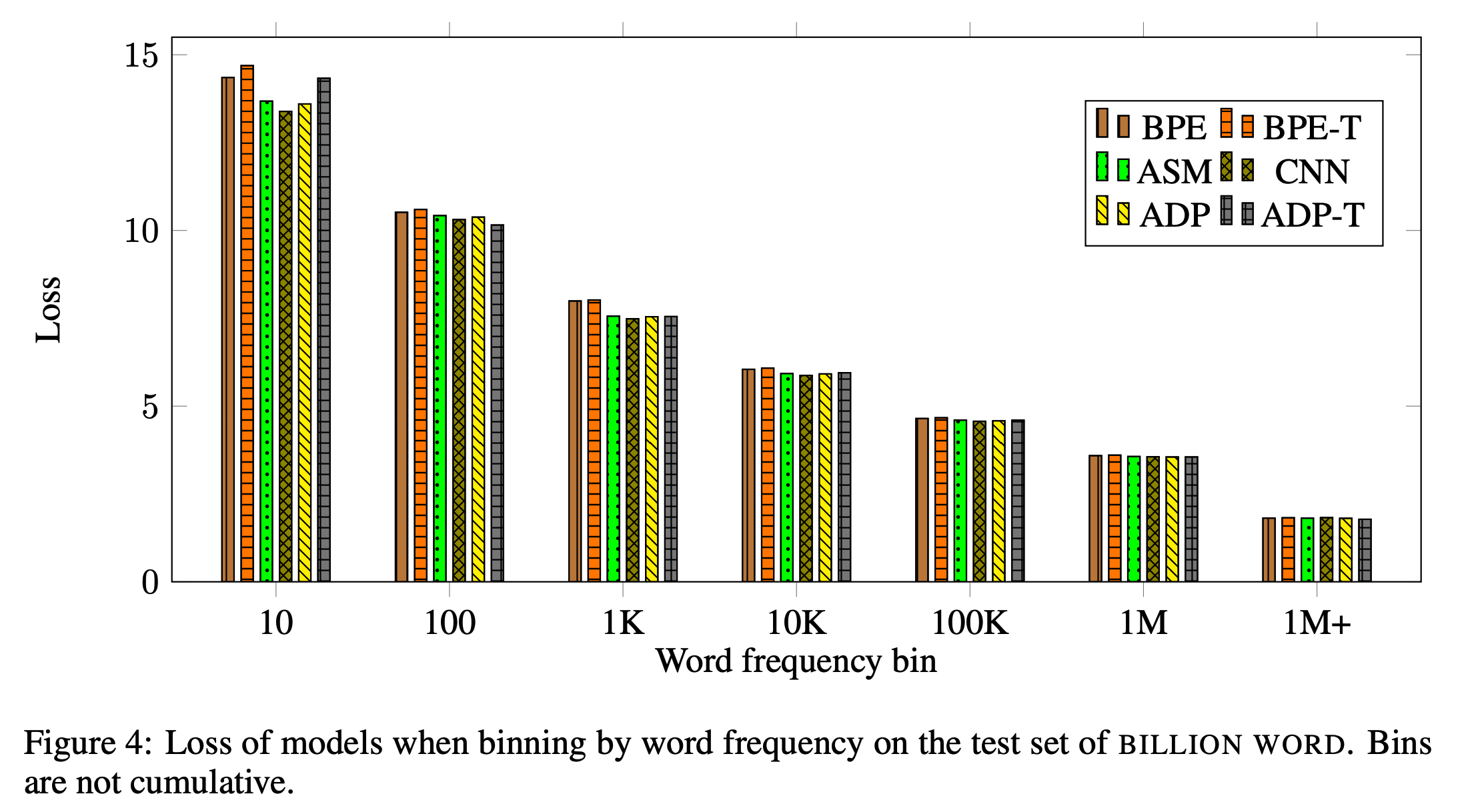
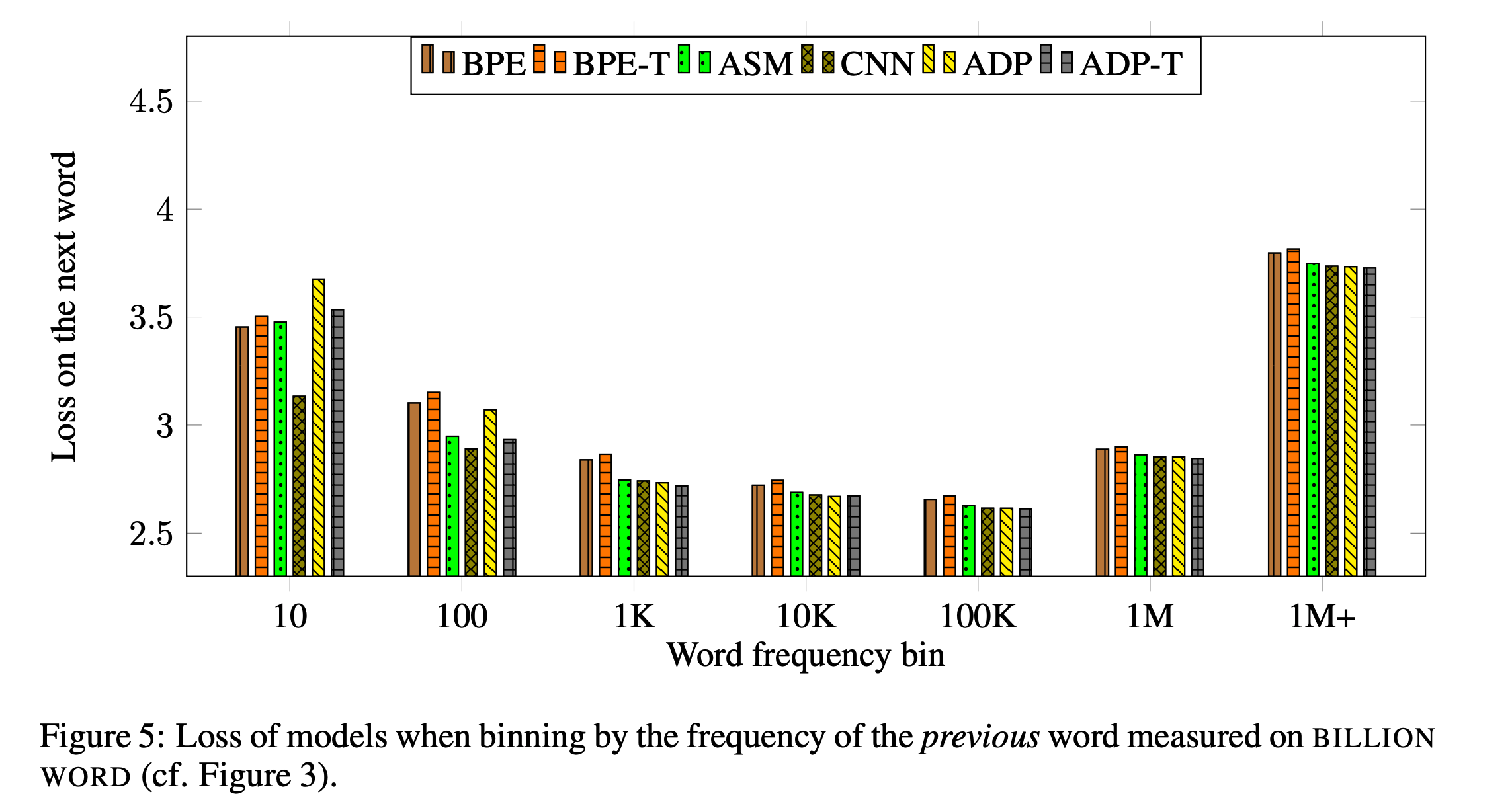
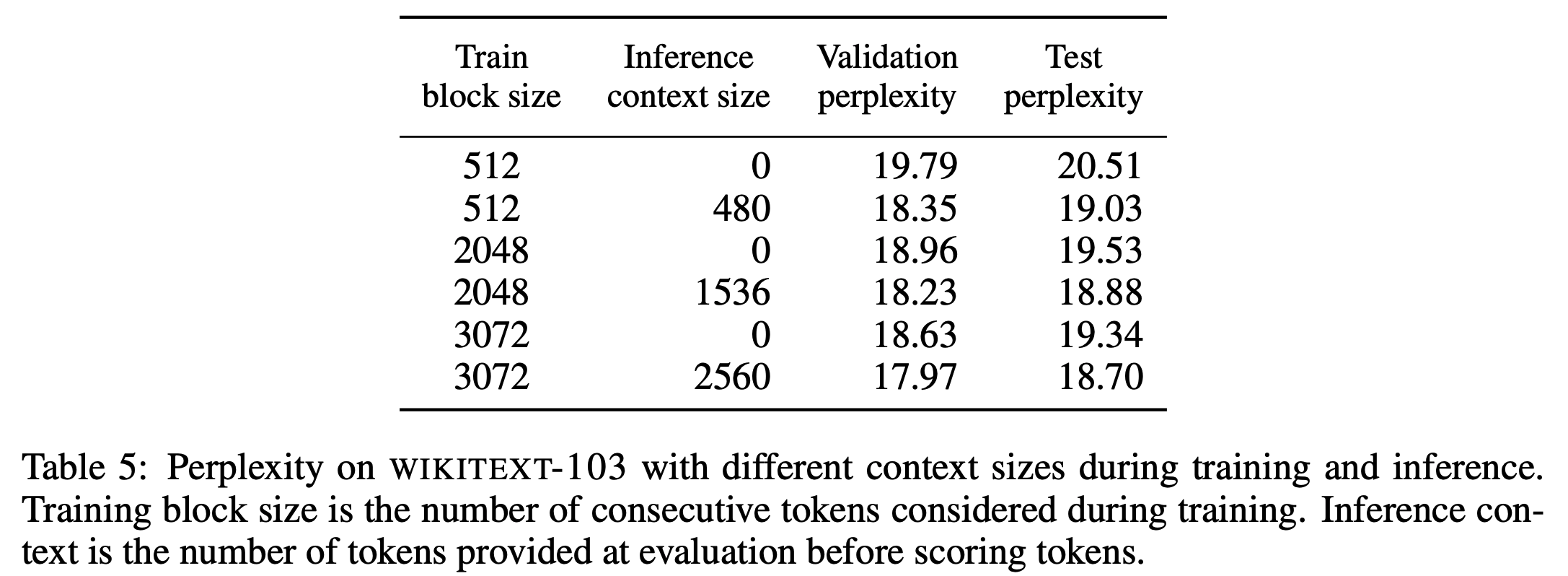
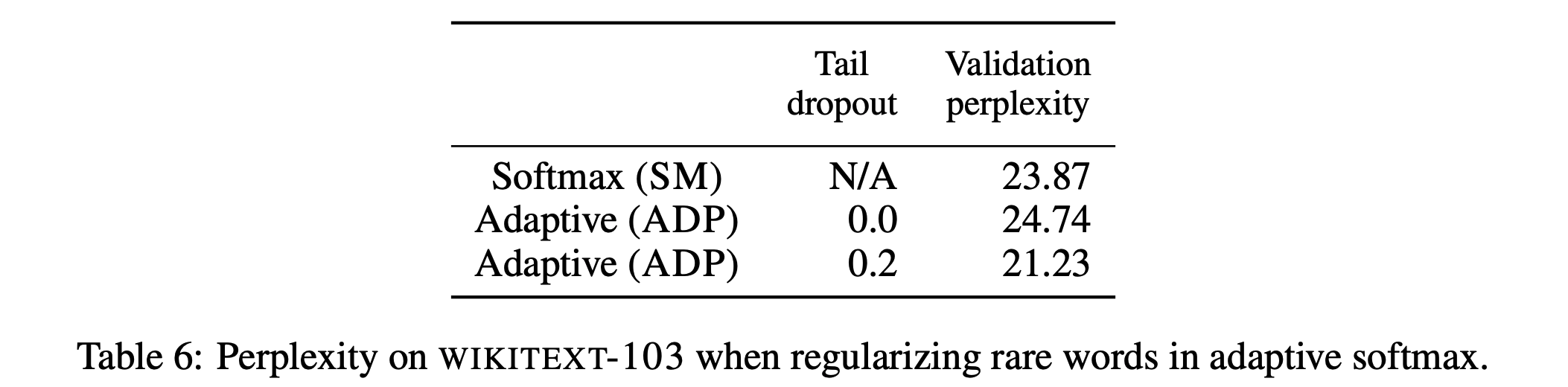
5.4. Adaptive Softmax vs. Full Softmax
6. Conclusion
- Adaptive input embeddings은 input word의 embedding size를 다르게 가져가면서 성능을 향상시켰고 모델 parameter의 수는 크게 감소시켰음
- Adaptive softmax(output)과 tying을 통해 parameter sharing을 하면 더욱 parameter 수를 감소시키면 성능도 올리고 학습 속도를 빠르게 할 수 있음
- 다른 input and output layer factorization 방법들에 대해 비교 실험을 진행하였고 adaptive input representation이 가장 좋은 성능을 보였음
- Future work으로 다른 태스크에 이 방법을 적용해볼 것임

Joohong Lee
Machine Learning Researcher